

AI-Ready Data Infrastructure Is Just Good Data Engineering

March 23, 2026 - 7 min read

Author

AI workloads place heavy demands on data at every stage, from model training through to applications such as assistants, image and video generation, and automated workflows. A single training run can consume terabytes of data, and the same datasets often need to be reused, transformed, and served in different formats downstream.
This shift has pushed software teams closer to data engineering. Teams that once relied on one engineer to keep pipelines running now hire entire data engineering teams to manage ingestion, storage, and processing for machine learning workloads.
AI also introduced a wave of new concepts, many of which describe workflows data engineers have been building for years. Feature stores, RAG, and orchestration systems often reuse patterns from warehouses and ETL jobs, just adapted for model training and serving.
This piece explains what “AI-ready” data infrastructure means in practice, how to adapt existing systems to support it, and which ideas are genuinely new versus renamed versions of established approaches.
The Reality of AI-Ready Data Infrastructure Today
A few years into the AI race, many companies have moved from experimentation to production use cases. Around 40% of organisations describe themselves as AI mature.
A stricter assessment tells a different story. Only 22% meet the criteria for AI readiness when measured against data quality, governance, and operational standards.
Adoption has outpaced the foundations needed to support it. Internal dashboards and early wins with AI features can give the impression of maturity, while gaps remain in data pipelines, access controls, and lifecycle management.
Leaders are aware of the gap. Gartner reports that 29% of organisations rank AI-ready data initiatives as their top priority over the next two to three years.
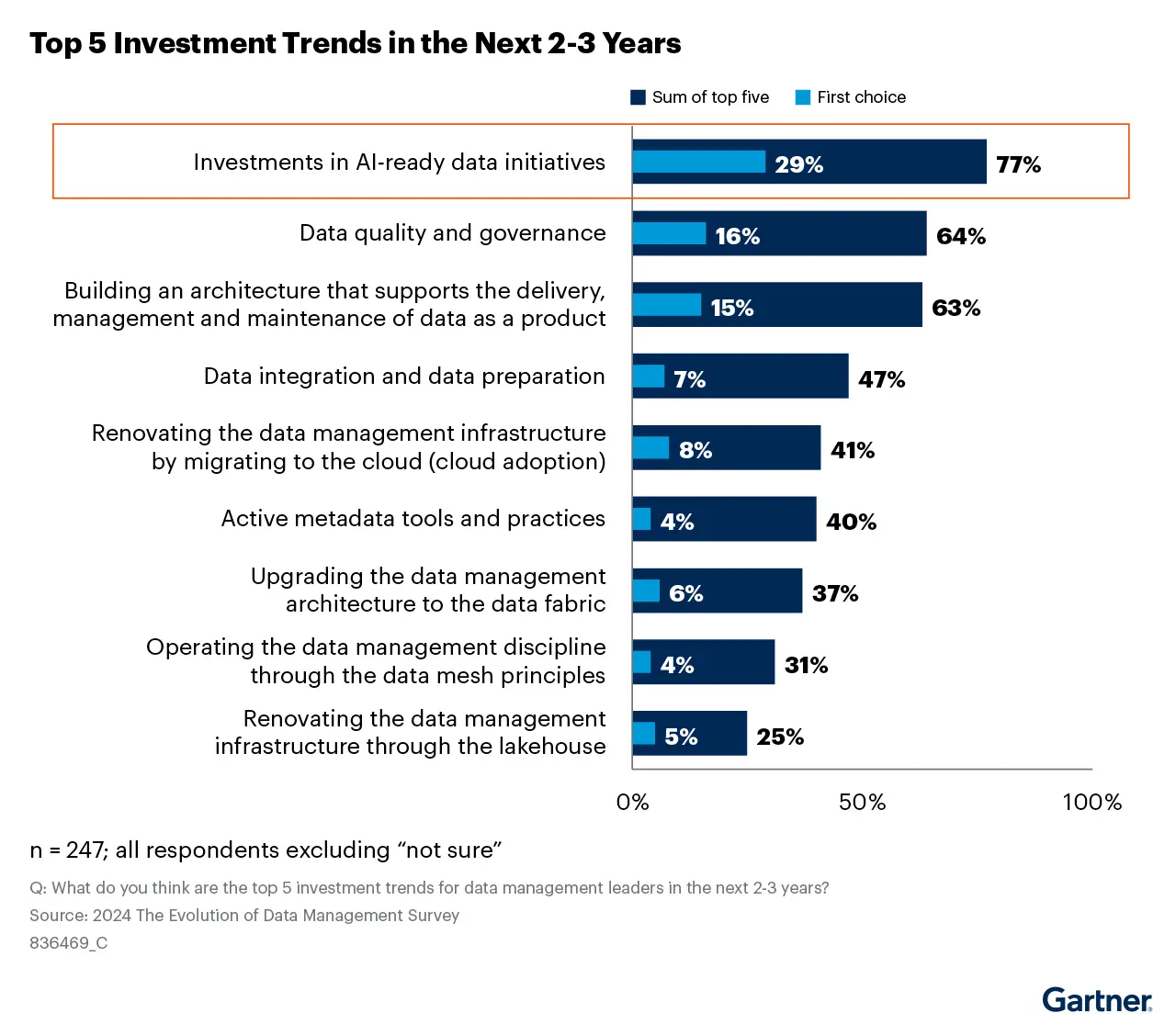 Still, data remains the main constraint. 52% of companies point to data quality and availability as the primary barrier to further AI adoption.
Still, data remains the main constraint. 52% of companies point to data quality and availability as the primary barrier to further AI adoption.
These numbers show a clear mismatch. Many organisations are building AI systems without the supporting data infrastructure. In practice, that limits model performance and can introduce risks, such as exposing sensitive data or relying on poorly governed sources.
Many teams approach AI in reverse.
The common model is a data hierarchy, where collection, storage, and transformation sit at the base, and AI sits at the top. In practice, companies often focus on the top layer first.
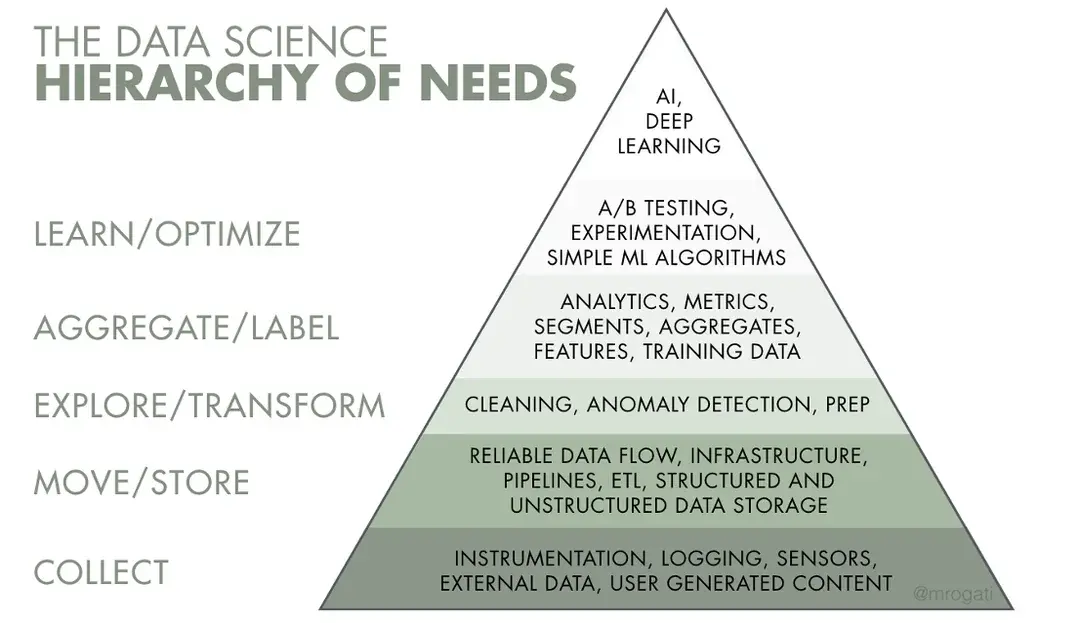 Illustration from the book Fundamentals of Data Engineering
Illustration from the book Fundamentals of Data Engineering
Work tends to concentrate on models, prompts, and experimentation, while data collection, cleaning, and pipeline reliability receive less attention. This inversion creates fragile systems. When the lower layers are weak, improvements at the model level have limited impact and are harder to sustain.
Understanding the Gap in AI-Ready Data Infrastructure
What drives low AI readiness scores, and why do companies still struggle to build the right foundations?
Let’s find the answer.
Data Engineering Wasn’t a Priority Before AI
Before the widespread use of LLMs, many organisations treated data work as secondary. “Data-driven” culture often meant basic reporting, and even tech companies applied it unevenly.
Dedicated data engineering teams were uncommon, especially outside of technical organisations. Pipelines, if they existed, were maintained by a small number of engineers and seen as back-office support rather than core infrastructure.
This changed as AI systems began to rely on large, well-structured datasets. MIT Technology Review reports that 72% of technology leaders now see data engineers as integral to the business. Their influence has grown as well: 66% help choose tools and vendors, and more than half are involved in decisions about data strategy and model usage.
Demand shows up clearly in compensation. Average data engineer salaries in the US rose from $113,000 in early 2023 to $153,000 in 2024-2025, reflecting the need to build and maintain AI data infrastructure.
The data landscape changed drastically
The data landscape has expanded rapidly over the past decade. In 2012, the MAD landscape, an annual map of the machine learning, AI, and data ecosystem, listed around 100 companies.
By 2025, that number reached 1,150 on the same map, and even that is a reduced view. The creator notes that the full ecosystem exceeds 2,000 companies, but many are excluded to keep the map readable.
 This growth means data teams face a constant stream of new tools. Engineers are expected to evaluate, adopt, and integrate them into existing stacks, often replacing parts of the infrastructure to support better performance or more accessible data connectors.
This growth means data teams face a constant stream of new tools. Engineers are expected to evaluate, adopt, and integrate them into existing stacks, often replacing parts of the infrastructure to support better performance or more accessible data connectors.
Many of these tools target narrow use cases rather than general improvements. A pipeline that works well for batch analytics may not suit real-time feature serving, so teams end up stitching together multiple specialised systems. At the same time, AI systems depend on fresh and accurate data, which raises the bar for how these tools are selected and operated.
What We Call AI-Ready Data Infrastructure Is Just Good Data Engineering
AI introduced a new layer of terminology, often packaged as something entirely new. In practice, many of these concepts map directly to workflows data engineers already handle, such as pipeline orchestration, data quality checks, and serving layers.
Most of the requirements for AI-ready data infrastructure come down to having reliable ingestion, well-defined schemas, and systems that can serve data consistently to both analytics and models.
It helps to translate these terms back into familiar patterns. Doing that makes it clearer what “AI-ready data infrastructure” actually includes and where gaps tend to appear.
AI apps are ETL pipelines with an uncontrolled transform layer
AI applications follow the same structure as ETL pipelines. Data moves through a sequence of steps, changes along the way, and the final output depends on everything that happened earlier in the flow.
The difference sits in the transform layer. An LLM takes input and produces output that isn’t fully deterministic or controllable. Each retrieval step, memory lookup, or external tool call adds another transformation, often with its own variability.
The most common mistake is treating a model as a standalone system. In practice, it behaves like one step in a larger pipeline. Strong AI applications focus on how data is prepared before it reaches the model and how the output is validated, filtered, or enriched afterwards.
Vector databases are indexes on top of unstructured data
Most AI datasets don’t come as clean tables. They arrive as collections of JSON files, images, audio, or video, often loosely structured and inconsistently organised. Sometimes there is basic metadata alongside the files. In other cases, metadata is incomplete, split across sources, or reconstructed at query time.
When data and metadata are tightly coupled to raw objects, even simple operations become expensive. Filtering or joining records requires reading the underlying files, which slows everything down.
Data engineering addresses this by adding structure. Datasets are represented as tables, metadata is separated from raw objects, and schemas define how data is stored and updated. Once data is organised into rows and columns, teams can filter, join, and version it without scanning entire datasets.
Vector databases sit on top of this structure as a specialised index. After unstructured data is embedded, it becomes another column, typically a high-dimensional vector linked to each record. The challenge then shifts to retrieval, where similarity matters more than exact matches.
A vector database handles this by indexing vectors for distance-based search. From a data engineering perspective, this is an index choice where you trade exact matches for faster approximate results.
Similarity search introduces uncertainty into systems that usually expect deterministic behaviour. With well-structured data, this can be controlled through filters and constraints. Without that structure, the index becomes the system, and its limitations define the behaviour of everything built on top.
RAG is a fancier name for data enrichment
In a RAG setup, the model generates output using external data that is similar to the input query.
This follows a familiar pattern from data engineering. It is a form of data enrichment, where context is added before producing the final result. The difference is that matching is based on similarity rather than exact keys. When the wrong context is retrieved, output quality drops, much like a bad join affecting downstream results.
It helps to think of RAG as a lookup join. The quality of the output depends less on the prompt and more on the data being retrieved. Freshness, completeness, and accuracy all play a direct role. If the underlying data is outdated or biased, the result will reflect those issues.
Focus on the source tables. Check how often they are updated, how the data is extracted, and how retrieval is performed. These factors determine whether RAG produces reliable results.
Agents are workflows without a fixed sequence
An agent is a process that maintains context as it runs. It takes input, performs actions, produces output, and carries forward state that affects what happens next.
The building blocks remain familiar. There are still steps, data moving between them, and state stored along the way. The difference is that the sequence is not fully predefined. The system decides what to do next during execution.
Those decisions come from model output. A response can trigger another lookup, call an external tool, generate intermediate data, or stop the process. The path forms as the system runs rather than being fully designed in advance.
This flexibility reduces predictability. The same input can lead to different outcomes, and failures are harder to trace because the execution path changes. Debugging often happens after the run, based on logs and outputs, rather than by inspecting a fixed flow.
From a data engineering perspective, the core work stays the same. You still define steps, control how state is stored and passed, decide what can be retried, and limit non-deterministic behaviour. These controls become more important when parts of the workflow are decided at runtime.
Orchestration turns messy agent workflows into manageable systems
Once an AI system includes more than a single model call, coordination becomes necessary. You need to define execution order, control how data moves between steps, and handle failures when they occur.
Tools like LangChain or LlamaIndex make this structure explicit. They define how steps connect, how intermediate results are passed, and where retries or branching happen.
Without orchestration, it becomes difficult to trace what ran, in what order, or why a specific result was produced.
For data engineers, orchestration keeps execution understandable, limits the impact of failures, and allows the system to scale without becoming unmanageable.

About the Author
Abdul Qayyum
With more than 17 years in software development, Abdul is a Software Architect has extensive expertise in Java, Big Data, AI/ML, and Blockchain technologies. His main role is to deliver strong architecture for back-end and middleware solutions to our clients across diverse business domains, including Telco, E-commerce, Blockchain, Media Streaming, Social Apps, and IoT.


Accelerate Your Projects With Our On-Demand Developers
Let's TalkTalent Shortage Holding You Back? Scale Fast With Us
Frequently Asked Questions
How do you handle different time zones?

With a team of 150+ expert developers situated across 5 Global Development Centers and 10+ countries, we seamlessly navigate diverse timezones. This gives us the flexibility to support clients efficiently, aligning with their unique schedules and preferred work styles. No matter the timezone, we ensure that our services meet the specific needs and expectations of the project, fostering a collaborative and responsive partnership.
What levels of support do you offer?
We provide comprehensive technical assistance for applications, providing Level 2 and Level 3 support. Within our services, we continuously oversee your applications 24/7, establishing alerts and triggers at vulnerable points to promptly resolve emerging issues. Our team of experts assumes responsibility for alarm management, overseas fundamental technical tasks such as server management, and takes an active role in application development to address security fixes within specified SLAs to ensure support for your operations. In addition, we provide flexible warranty periods on the completion of your project, ensuring ongoing support and satisfaction with our delivered solutions.
Who owns the IP of my application code/will I own the source code?
As our client, you retain full ownership of the source code, ensuring that you have the autonomy and control over your intellectual property throughout and beyond the development process.
How do you manage and accommodate change requests in software development?
We seamlessly handle and accommodate change requests in our software development process through our adoption of the Agile methodology. We use flexible approaches that best align with each unique project and the client's working style. With a commitment to adaptability, our dedicated team is structured to be highly flexible, ensuring that change requests are efficiently managed, integrated, and implemented without compromising the quality of deliverables.
What is the estimated timeline for creating a Minimum Viable Product (MVP)?
The timeline for creating a Minimum Viable Product (MVP) can vary significantly depending on the complexity of the product and the specific requirements of the project. In total, the timeline for creating an MVP can range from around 3 to 9 months, including such stages as Planning, Market Research, Design, Development, Testing, Feedback and Launch.
Do you provide Proof of Concepts (PoCs) during software development?
Yes, we offer Proof of Concepts (PoCs) as part of our software development services. With a proven track record of assisting over 70 companies, our team has successfully built PoCs that have secured initial funding of $10Mn+. Our team helps business owners and units validate their idea, rapidly building a solution you can show in hand. From visual to functional prototypes, we help explore new opportunities with confidence.
Are we able to vet the developers before we take them on-board?
When augmenting your team with our developers, you have the ability to meticulously vet candidates before onboarding. We ask clients to provide us with a required developer’s profile with needed skills and tech knowledge to guarantee our staff possess the expertise needed to contribute effectively to your software development projects. You have the flexibility to conduct interviews, and assess both developers’ soft skills and hard skills, ensuring a seamless alignment with your project requirements.
Is on-demand developer availability among your offerings in software development?
We provide you with on-demand engineers whether you need additional resources for ongoing projects or specific expertise, without the overhead or complication of traditional hiring processes within our staff augmentation service.
Do you collaborate with startups for software development projects?
Yes, our expert team collaborates closely with startups, helping them navigate the technical landscape, build scalable and market-ready software, and bring their vision to life.
Our startup software development services & solutions:
- MVP & Rapid POC's
- Investment & Incubation
- Mobile & Web App Development
- Team Augmentation
- Project Rescue
Subscribe to our blog
Related Posts
Get in Touch with us
Thank You!
Thank you for contacting us, we will get back to you as soon as possible.
Our Next Steps
- Our team reaches out to you within one business day
- We begin with an initial conversation to understand your needs
- Our analysts and developers evaluate the scope and propose a path forward
- We initiate the project, working towards successful software delivery