




For years, organizations focused on structured data: information neatly organized in rows and columns that could easily feed dashboards and reports. But much of the valuable context in a business lives outside those systems: in emails, documents, chat logs, PDFs, support tickets, logs, and other unstructured formats.
Working with this kind of data requires more than traditional analytics. Specialists today look for tools that can extract meaning from large document collections, power semantic search, support AI workflows like RAG, and turn messy content into actionable insight.
In this article, we explore 10 leading unstructured data analytics tools, highlighting how they help teams analyze, retrieve, and operationalize unstructured information at scale.
Top 10 Unstructured Data Analytics Tools
Elasticsearch and Kibana
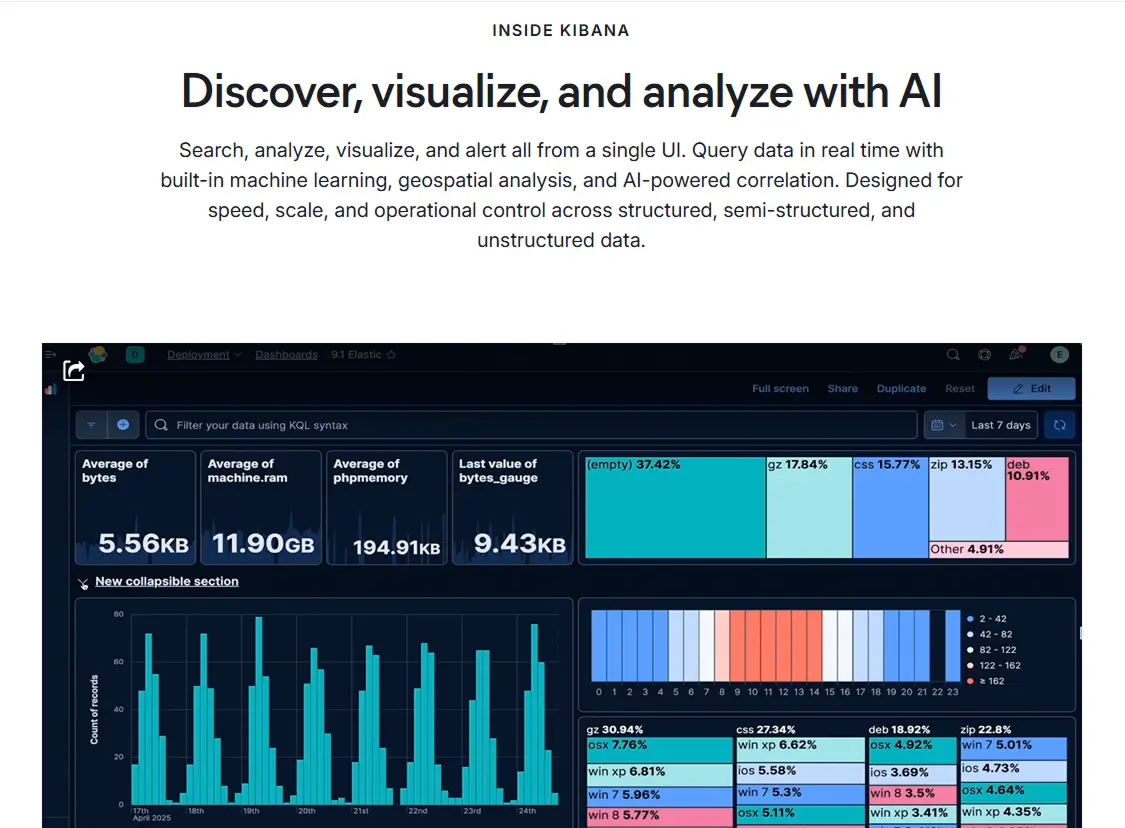 Elastic Kibana is the analytics and visualization layer for Elasticsearch, designed to turn high-volume, unstructured and semi-structured data into operational insight. In practice, it is strongest when organizations need one interface for exploratory search, dashboarding, anomaly detection, geospatial analysis, and alerting across logs, documents, metrics, traces, and event streams. For AI-heavy workflows, Kibana is increasingly tied to semantic/vector search, natural-language querying, and Retrieval-Augmented Generation (RAG) pipelines built on the Elastic Search AI Platform.
Elastic Kibana is the analytics and visualization layer for Elasticsearch, designed to turn high-volume, unstructured and semi-structured data into operational insight. In practice, it is strongest when organizations need one interface for exploratory search, dashboarding, anomaly detection, geospatial analysis, and alerting across logs, documents, metrics, traces, and event streams. For AI-heavy workflows, Kibana is increasingly tied to semantic/vector search, natural-language querying, and Retrieval-Augmented Generation (RAG) pipelines built on the Elastic Search AI Platform.
From a strategic standpoint, Kibana performs best as part of the broader Elastic stack: data is ingested from cloud, app, security, and business systems, indexed in Elasticsearch, then surfaced in Kibana for analysis and action. This makes it suitable for teams that want search, observability, and security analytics on a common data platform rather than isolated point tools.
Elastic reports that more than 50% of the Fortune 500 rely on its platform, and public company information highlights a global workforce of 3,000+ employees.
Key Strengths & Specializations
- Unified analytics for unstructured data: Kibana supports querying and visualizing unstructured, structured, and semi-structured data in one interface, reducing tool sprawl for cross-functional teams.
- Search + semantic retrieval foundation: Through Elasticsearch capabilities exposed in Kibana workflows, teams can combine lexical search, vector search, and hybrid retrieval for document intelligence and AI search use cases.
- AI/ML-assisted operations: Built-in machine learning features support anomaly detection, pattern discovery, and alerting workflows that help teams detect issues earlier in large event streams.
- Strong ingestion and integration ecosystem: Elastic provides broad ingestion options (agents, connectors, APIs) and cloud integrations, which is valuable for organizations consolidating data from heterogeneous sources.
- Operational decision support at scale: Real-time dashboards, drilldowns, and alerting allow technical and business teams to move from raw event data to monitored KPIs and incident response workflows.
Ideal Use Case
Kibana is ideal for platform engineers, SRE/observability teams, security operations teams, data engineers, and analytics leaders who need fast insight from high-volume machine and text-heavy data. It is especially effective in organizations already running Elasticsearch or pursuing a consolidated search-observability-security analytics architecture.
Best-fit environments include cloud-native stacks (AWS/Azure/GCP), microservices, containerized workloads, and data setups where logs, traces, and operational events must be correlated with business or document-centric data. For AI initiatives, Kibana is a strong fit when teams need to operationalize semantic retrieval and monitor the behavior of search-driven applications.
Pricing Model
Elastic uses multiple commercial models depending on deployment approach:
- Serverless (Elastic Cloud Serverless): usage-based pricing with pay-as-you-go or prepaid consumption.
- Hosted (Elastic Cloud): resource-based pricing with pay-as-you-go or prepaid annual commitments.
- Self-managed: license-based pricing (commonly tied to node/RAM footprint), with feature access by subscription tier.
Self-managed Subscription Tiers (Elastic subscriptions)
- Basic: free and open tier for core capabilities.
- Platinum: paid tier for advanced security, ML, alerting, and enterprise capabilities.
- Enterprise: highest tier with advanced AI/search and enterprise-grade governance/support options.
- Gold: discontinued for new self-managed customers.
Serverless Search Pricing (public list prices)
- Ingest: from $0.14 per VCU/hour.
- Search: from $0.09 per VCU/hour.
- ML: from $0.07 per VCU/hour.
- Storage retained: from $0.047 per GB/month.
- Data egress: from $0.05 per GB/month (with some profile-specific free allowances).
- Elastic managed LLM: $4.50 per million input tokens and $21 per million output tokens.
- Elastic Inference Service: from $0.08 per million tokens.
Note: Effective spend varies materially by ingestion volume, retention period, query intensity, and ML/inference usage. Enterprise buyers should model both infrastructure and support uplift when comparing total cost of ownership.
Notable Projects
- Akeneo modernized search operations on Elastic Cloud: Achieved 99.9% uptime, completed migration in 5 months with zero customer impact, improved performance by 3x, cut server footprint by 30%, reduced operating costs by 50%, and accelerated release cadence from weekly to every 30 minutes.
- SproutsAI built AI-driven go-to-market intelligence on Elastic: Used Elastic for semantic search, predictive analytics, and RAG-centric workflows over 400M+ records from 40+ sources, reporting up to 60% growth in qualified pipeline, 85% ICP mapping accuracy, and 50% sales-efficiency gains.
Customer Reviews and Considerations
Review Scores (platform snapshots)
- TrustRadius (Elasticsearch listing): 8.7/10 (217 ratings).
- G2 (Elastic Stack listing): 4.5/5 (95 reviews).
What Customers Commonly Admire
- Powerful search-and-analytics depth at scale, especially for teams correlating logs, metrics, traces, and event data across distributed systems.
- Flexible dashboards and investigation workflows in Kibana that help teams move quickly from signal detection to root-cause analysis.
Areas Buyers Should Evaluate Carefully
- Learning curve and operational complexity: multiple users report that onboarding, query design, and cluster operations can require experienced practitioners.
- Resource and cost management: reviewers frequently note that performance tuning, retention strategy, and sizing discipline are critical to avoiding unexpected spend in large-scale environments.
Practical Buyer Considerations
- Prioritize architecture and governance early: define index lifecycle policies, retention windows, and role-based access controls before broad rollout.
- Validate operating model fit: if your team has limited Elastic expertise, budget for enablement or managed support to reduce implementation risk.
Algolia Search & Discovery
 Algolia Search & Discovery is an AI retrieval platform designed for high-speed discovery across product catalogs, help centers, and content-heavy applications. For unstructured and semi-structured workloads, the platform combines keyword retrieval with vector retrieval, NLP-driven query understanding, personalization, and rules-based ranking.
Algolia Search & Discovery is an AI retrieval platform designed for high-speed discovery across product catalogs, help centers, and content-heavy applications. For unstructured and semi-structured workloads, the platform combines keyword retrieval with vector retrieval, NLP-driven query understanding, personalization, and rules-based ranking.
Teams can ingest data through APIs, connectors, and a hosted crawler, then tune relevance with analytics, A/B testing, synonyms, query categorization, and dynamic re-ranking.
Algolia reports more than 18,000 customers in 150+ countries, and SourceForge lists the company founding year as 2012. This places the product in a mature operating window for enterprise search and AI-driven discovery programs.
Key Strengths & Specializations
- Hybrid retrieval for unstructured discovery: keyword + vector search, NLP features, typo tolerance, and intent-focused ranking.
- Fast operational search: Algolia positions average response times below 20 ms for production workloads.
- Developer and product workflow fit: API-first architecture, SDKs, dashboard tuning, and broad integrations across ecommerce and headless stacks.
- AI-enabled optimization: personalization, AI synonyms, query categorization, dynamic re-ranking, and experiment tooling.
- Enterprise scale and control: global infrastructure, security certifications, SSO, SLAs, and high-availability options in upper tiers.
Ideal Use Case
Best fit is digital product teams, ecommerce leaders, and platform engineering teams that need search and semantic retrieval as a core part of revenue or self-service journeys. It integrates well with headless commerce and API-driven stacks (Shopify, Salesforce Commerce Cloud, Adobe Commerce, custom React/Next.js, and similar architectures), especially when teams need fast time to value without building search infrastructure in-house.
Pricing Model
Algolia uses tiered usage pricing built around search requests and records.
- Build: Free. Includes 10K search requests/month, 1M records, 10K AI Recommendation requests/month, 10K crawls/month, and one Generative Experience Guide.
- Grow: 10K search requests/month included, then $0.50 per additional 1K search requests. 100K records included, then $0.40 per additional 1K records.
- Grow Plus: 10K search requests/month included, then $1.75 per additional 1K search requests. 100K records included, then $0.40 per additional 1K records.
- Elevate (annual): custom pricing, custom search/record volumes, plus enterprise capabilities such as NeuralSearch, AI Collections, real-time personalization, SSO, and enhanced SLA.
Notable Projects
- Cafeyn increased search queries 3x, raised subscriptions by 10%, and improved search/discovery speed by over 2x after moving from an open-source setup to Algolia (case study).
- StuDocu reported 20%+ conversion improvement, lower maintenance cost versus Elasticsearch, and easier no-code tuning for relevance experiments (case study).
Customer Reviews and Considerations
Capterra rates Algolia at 4.7/5 (74 reviews), and SourceForge shows 4.4/5 (5 reviews).
What users praise:
- Very fast search performance and quick integration into web stacks.
- Strong relevance tooling and useful analytics for tuning.
What users flag for improvement:
- Cost pressure at scale and invoice volatility during traffic spikes.
- Setup and governance complexity for advanced implementations, including documentation and dashboard learning curve.
Microsoft Azure AI Search
 Microsoft Azure AI Search is an enterprise retrieval platform for unstructured data workloads in RAG and agentic AI. It supports hybrid retrieval (keyword plus vector), semantic ranker, and agentic retrieval for query planning, reranking, and answer synthesis.
Microsoft Azure AI Search is an enterprise retrieval platform for unstructured data workloads in RAG and agentic AI. It supports hybrid retrieval (keyword plus vector), semantic ranker, and agentic retrieval for query planning, reranking, and answer synthesis.
For ingestion and integration, it provides indexers and data pipeline tooling across Azure Blob Storage, Microsoft 365 SharePoint, OneLake, data lakes, enterprise data sources, and web content.
In practice, teams use it to ground copilots, knowledge assistants, and search-driven analytics with high-relevance document retrieval.
Key Strengths and Specializations
- Hybrid and vector search with semantic reranking for higher retrieval precision in unstructured document sets.
- Built-in RAG and agent workflows, including agentic retrieval and Foundry integrations.
- Broad enterprise connectors and indexing paths for document-heavy environments.
- Strong security and compliance alignment for regulated sectors.
- Flexible deployment scale from small pilots to high-throughput production services.
Ideal Use Cases
Best fit for AI engineers, data platform teams, search specialists, and enterprise architects building production RAG systems over internal documents. It integrates well with Azure OpenAI, Azure AI Foundry, Microsoft 365 data estates, and existing Azure storage and governance controls. It is especially useful when teams need both relevance tuning and enterprise operations in one stack.
Pricing Model
Azure AI Search uses tiered infrastructure pricing plus feature-based usage pricing.
- Service tiers (Central US, monthly, default compute):
- Free: $0
- Basic: $73.73
- Standard S1: $245.28
- S2: $981.12
- S3: $1,962.24
- Storage Optimized L1: $2,802.47
- L2: $5,604.21 per search unit.
- Agentic retrieval: first 50M tokens free per month, then $0.022 per 1M tokens (model token costs billed separately).
- Semantic ranker: first 1,000 requests free per month, then $1 per 1,000 requests.
Notable Projects
- Beth Israel Lahey Health built ChatPPGD with Azure AI Search, Azure OpenAI, and Document Intelligence, reaching 98% response accuracy and 800+ staff queries per week. [Case study]
- Fujitsu used Azure AI Agent Service with Azure AI Search for proposal automation, reporting 67% productivity improvement and rollout to about 38,000 users. [Case study]
Customer Reviews and Considerations
G2 lists Azure AI Search at 4.5/5 (32 reviews). Gartner Peer Insights shows 4.3/5 (53 ratings in Search and Product Discovery, 197 ratings across markets).
What customers praise:
- Fast setup, strong integration with Azure services, and useful hybrid or semantic retrieval quality.
- Enterprise scalability and governance fit for production AI search.
Common improvement themes:
- Cost sensitivity versus alternatives, especially for smaller teams and high-throughput usage.
- Learning curve around schema design, chunking strategy, and tuning for domain-specific relevance.
IBM Watson Discovery
 IBM Watson Discovery is IBM’s unstructured data analytics and semantic retrieval tool for enterprise search, research, and workflow automation. It combines document ingestion, OCR, Smart Document Understanding, natural language enrichment, and relevance tuning so teams can query contracts, policies, reports, emails, and web content in one place.
IBM Watson Discovery is IBM’s unstructured data analytics and semantic retrieval tool for enterprise search, research, and workflow automation. It combines document ingestion, OCR, Smart Document Understanding, natural language enrichment, and relevance tuning so teams can query contracts, policies, reports, emails, and web content in one place.
The platform supports faceted search, passage retrieval, JSON outputs for downstream systems, and connectors such as SharePoint, Salesforce, Box, IBM Cloud Object Storage, and FileNet. It is used in AI-heavy workflows that need entity extraction, sentiment and concept analysis, and retrieval support for assistants built with IBM watsonx.
Key Strengths & Specializations
- Strong document intelligence for complex files, including layout-aware extraction for tables and sections.
- Enterprise-grade semantic search and passage retrieval across large, mixed-format corpora.
- Built-in NLP enrichments (entities, keywords, sentiment, emotion, categories, concepts) plus custom model tuning.
- Flexible deployment and governance options through IBM Cloud and Cloud Pak for Data.
- Practical integration model for data-heavy environments that already run IBM, Microsoft, and SaaS content systems.
Ideal Use Case
Watson Discovery fits data science leaders, AI product teams, knowledge management owners, and compliance operations that need reliable answers from large unstructured repositories. It works well in regulated environments (financial services, insurance, healthcare, legal, public sector) where traceability, security, and multilingual content matter.
It performs best when paired with enterprise content stores and a workflow stack that can consume API outputs for automation, agent assistance, or analyst research.
Pricing Model
IBM publishes tiered pricing for Watson Discovery on IBM Cloud:
- Plus: starts at $500/month, includes 10,000 documents and 10,000 queries.
- Enterprise: starts at $5,000/month, includes 100,000 documents and 100,000 queries.
- Premium: custom pricing (contact sales), includes much higher scale (pricing page shows 1,000,000 documents).
- Cloud Pak for Data cartridge: custom pricing.
For Plus plans, IBM also publishes overage rates of $50 per additional 1,000 documents and $20 per additional 1,000 queries.
Notable Projects
- Crédit Mutuel: IBM Watson-supported assistant capabilities helped service teams respond faster, with IBM citing about 60% faster expert service and daily handling support across high inquiry volumes.
- HSBC Asset Management (via EquBot): IBM cites AI-driven investment workflows using Watson Discovery for unstructured analysis, with business outcomes including more than $2 billion in sales linked to the platform.
Customer Reviews and Considerations
The product has broad enterprise adoption signals in analyst and peer-review channels, with 4.6/5 on Gartner Peer Insights (85 ratings), 4.5/5 on G2 (97 reviews), and 9.1/10 on TrustRadius (67 ratings/reviews).
What customers value most:
- Strong relevance and search depth across large document collections.
- Useful APIs and integration flexibility for enterprise AI projects.
Common concerns:
- Pricing can rise quickly as document/query volume grows.
- Setup quality depends on taxonomy, document preparation, and admin configuration; weaker setup leads to mixed early results.
Google Cloud Vertex AI Search
 Vertex AI Search is Google Cloud’s managed retrieval layer for enterprise unstructured data, built for websites, internal knowledge bases, and retrieval-augmented generation (RAG) in AI apps. It supports semantic retrieval across documents and structured records, connector-based ingestion from tools such as Google Drive, Slack, Jira, and Cloud Storage, and built-in processing steps such as OCR, chunking, embedding, indexing, and ranking.
Vertex AI Search is Google Cloud’s managed retrieval layer for enterprise unstructured data, built for websites, internal knowledge bases, and retrieval-augmented generation (RAG) in AI apps. It supports semantic retrieval across documents and structured records, connector-based ingestion from tools such as Google Drive, Slack, Jira, and Cloud Storage, and built-in processing steps such as OCR, chunking, embedding, indexing, and ranking.
The product also plugs into Document AI for document intelligence workflows and into Vertex AI Agent Builder for conversational and agentic experiences.
Key Strengths & Specializations
- Semantic and hybrid retrieval (keyword + vector) for enterprise content with relevance tuning controls.
- Managed ingestion and enrichment pipeline for unstructured corpora, including PDF/image text extraction and chunk-level indexing.
- Native fit with Google Cloud AI stack, including Vertex AI models, grounding checks, and security/governance controls.
- Industry-specific search packages (commerce, media, healthcare) that reduce setup effort for domain workflows.
Ideal Use Case
Vertex AI Search fits data and AI teams that already run on Google Cloud and need fast deployment of enterprise search or RAG without building their own retrieval infrastructure. It is especially effective for product search, internal knowledge assistants, and support automation where teams need connector-based ingestion, multilingual retrieval, and policy-aware access control.
Typical users include ML engineers, platform teams, and digital product owners working in GCP-first architectures.
Pricing Model
Google exposes two pricing approaches:
- General pricing: Standard at $1.50 per 1,000 queries, Enterprise at $4.00 per 1,000 queries, plus optional Advanced Generative Answers at $4.00 per 1,000 user-input queries. Storage charges apply.
- Configurable pricing: hourly subscription units for committed query throughput and storage (minimum commit published as 1000 QPM and 50 GB), with optional add-ons such as semantic ranking and generative answer packs.
Google Cloud offers new customers up to $1,000 in credits for early evaluation.
Notable Projects
- Toolstation: reduced no-result searches from 2% to 0.1%, increased click-through by 10%, and lifted search-driven revenue by 5.5%.
- AIHelp: reported 30% higher case-handling efficiency using Vertex AI Search in its support intelligence workflow.
Customer Reviews and Considerations
G2 lists Vertex AI Search at 3.9/5 (8 reviews, accessed March 5, 2026). Gartner Peer Insights search listings indicate low-to-mid 4.2/5 sentiment for related Vertex AI Search and Vertex AI listings.
Customers often praise fast integration with existing Google Cloud services and the ability to stand up semantic search without heavy custom infrastructure. Reported friction points include documentation gaps for edge cases, indexing behavior on complex datasets, and cost planning when query volume or advanced generative features scale.
Amazon Kendra (AWS)
 Amazon Kendra is AWS’s managed enterprise search and retrieval product for unstructured and structured content. It is built for semantic retrieval, natural-language Q&A, and RAG pipelines, including a Retriever API that returns optimized passages for LLM prompts.
Amazon Kendra is AWS’s managed enterprise search and retrieval product for unstructured and structured content. It is built for semantic retrieval, natural-language Q&A, and RAG pipelines, including a Retriever API that returns optimized passages for LLM prompts.
The service supports document intelligence workflows through Custom Document Enrichment, where teams can run preprocessing with AWS Lambda and services such as Textract, Comprehend, and Transcribe before indexing. It also supports relevance tuning, ACL-aware filtering, metadata filtering, search analytics dashboards, and query autocomplete.
For ingestion, Kendra provides native and partner connectors across repositories such as S3, SharePoint, Confluence, Salesforce, ServiceNow, databases, and web sources.
Key strengths & specializations
- High-accuracy semantic retrieval for enterprise content, including natural-language questions and passage-level answers.
- Strong fit for AI-heavy workflows through Kendra Retriever API for RAG, plus access control and relevance controls.
- Broad connector ecosystem for distributed document estates across SaaS, file stores, web, and databases.
- Built-in document enrichment path for OCR, entity extraction, classification, and custom ETL at ingestion time.
Ideal use cases
Kendra fits platform teams, data/AI engineers, knowledge management leaders, and support operations teams that need governed search over fragmented enterprise content. It works best in AWS-centric stacks that already use S3, IAM, Lambda, and Bedrock.
Common outcomes include faster employee knowledge retrieval, agent-assist for contact centers, and secure enterprise retrieval for LLM applications where permissions and source attribution matter.
Pricing model
Amazon Kendra pricing is capacity-based plus connector charges.
- GenAI Enterprise Edition: base index $0.32/hour (includes 1 storage unit + 1 query unit, up to 20,000 docs or 200 MB extracted text, and about 8,000 queries/day). Additional storage: $0.25/hour per unit, query capacity $0.07/hour per unit. Connectors are $30 per index per month.
- Basic Enterprise Edition: base index $1.40/hour (up to 100,000 docs or 30 GB extracted text, about 8,000 queries/day). Additional storage and query units are $0.70/hour each. Connector sync charges apply at $0.35/hour plus $1 per 1M scanned docs.
- Basic Developer Edition: $1.125/hour (up to 10,000 docs or 3 GB extracted text, about 4,000 queries/day), no add-on storage/query units.
- Free trial: up to 750 hours for the first 30 days on Basic Developer or GenAI Enterprise (connector usage excluded).
Notable projects
- The Wall Street Journal launched its Talk2020 search experience in 5 months with Amazon Kendra, adding natural-language search over 30 years of candidate statements and reporting strong engagement spikes during debate events. Case study:
- Magellan Rx Management reported a 9 to 15 second average call-time reduction after implementing agent-assist with Contact Center Intelligence and Amazon Kendra, saving more than 4,000 hours across 2.2 million calls per year. Customer story:
Customer reviews and considerations
Amazon Kendra has limited coverage on software review platforms.
- Gartner Peer Insights: 4.4/5 (8 ratings) for Amazon Kendra.
- PeerSpot: 3.8/5 (2 reviews).
What users praise most:
- relevance quality for natural-language enterprise search
- straightforward setup in AWS-native environments.
Main concerns:
Pricing and billing predictability for production workloads, and indexing/sync latency or setup complexity in some implementations.
Reddit discussions also echo these points, with positive feedback on search quality and recurring caution on cost governance.
Apache Solr
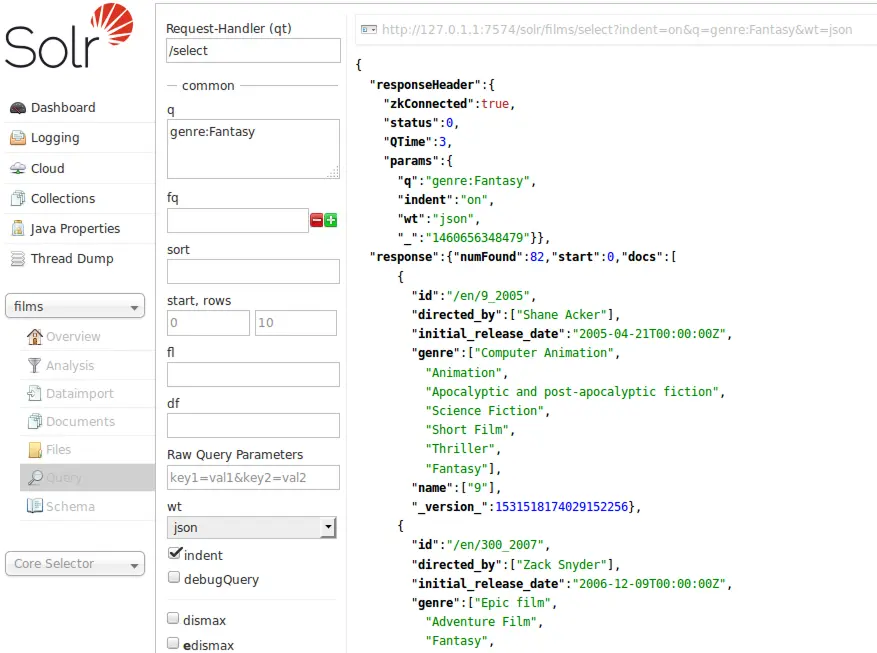 Apache Solr is Apache’s open-source search and unstructured data analytics platform, built on Lucene.
Apache Solr is Apache’s open-source search and unstructured data analytics platform, built on Lucene.
For enterprises handling document-heavy workloads, Solr combines full-text search, vector retrieval, geospatial search, faceting, and near real-time indexing in one engine. It supports JSON/XML/CSV ingestion over HTTP, rich document parsing via Apache Tika (PDF, Word, Office formats), multilingual text analysis, query suggestions, spell correction, clustering, and statistical aggregations. For AI and ML workflows, Solr’s dense vector search (kNN/HNSW) enables semantic retrieval and hybrid ranking patterns. Teams can also plug Solr into broader pipelines (Kafka, Spark, graph stores, ML model services) when building knowledge-centric applications.
Solr was established in 2006 as a Lucene subproject and became an Apache top-level project in 2021. As of March 3, 2026, Apache lists Solr 10.0.0 as the current release.
Key Strengths & Specializations
- Strong unstructured content handling through built-in rich document extraction and advanced analyzers.
- Mature search relevance controls (facets, boosting, synonyms, spelling, ranking tuning).
- Semantic retrieval support through dense vector indexing and kNN query parsers.
- Enterprise-scale operations via SolrCloud (replication, sharding, failover, high-query-volume support).
- Open architecture with REST APIs and plugin extensibility for domain-specific ranking and NLP enrichment.
Ideal Use Cases
Solr fits search engineers, data platform teams, and product teams building high-scale site search, product discovery, document retrieval, e-discovery, and support knowledge systems. It performs best in JVM-centric or API-first stacks where teams can tune relevance and operate distributed infrastructure. It is a strong fit when organizations want open-source control, custom ranking logic, and integration into existing data engineering pipelines.
Pricing Model
Apache Solr is free and open source under the Apache License 2.0, with no license fee or token-based pricing. Cost sits in infrastructure, operations, and optional commercial support/managed services from third parties.
Notable Projects
- Sitecore migration to managed Solr infrastructure improved stability and search quality during a platform upgrade and data center move, while accelerating delivery timelines.
- Jellyfish (for a leading online university) reports millions of monthly visits with SearchStax-backed Solr and cites 100% uptime and strong performance after migration. Source:
Customer Reviews And Considerations
G2 shows Apache Solr at 4.1/5 (26 reviews), and TrustRadius shows 8.8/10 (44 ratings).
What users praise most:
- Fast, relevant search for large catalogs and document corpora.
- Flexible filtering, faceting, and customization for complex search experiences.
Common concerns:
- Steep learning curve for schema design, relevance tuning, and operations.
- Admin and developer ergonomics can require extra effort, especially for teams seeking turnkey simplicity.
Mindbreeze InSpire
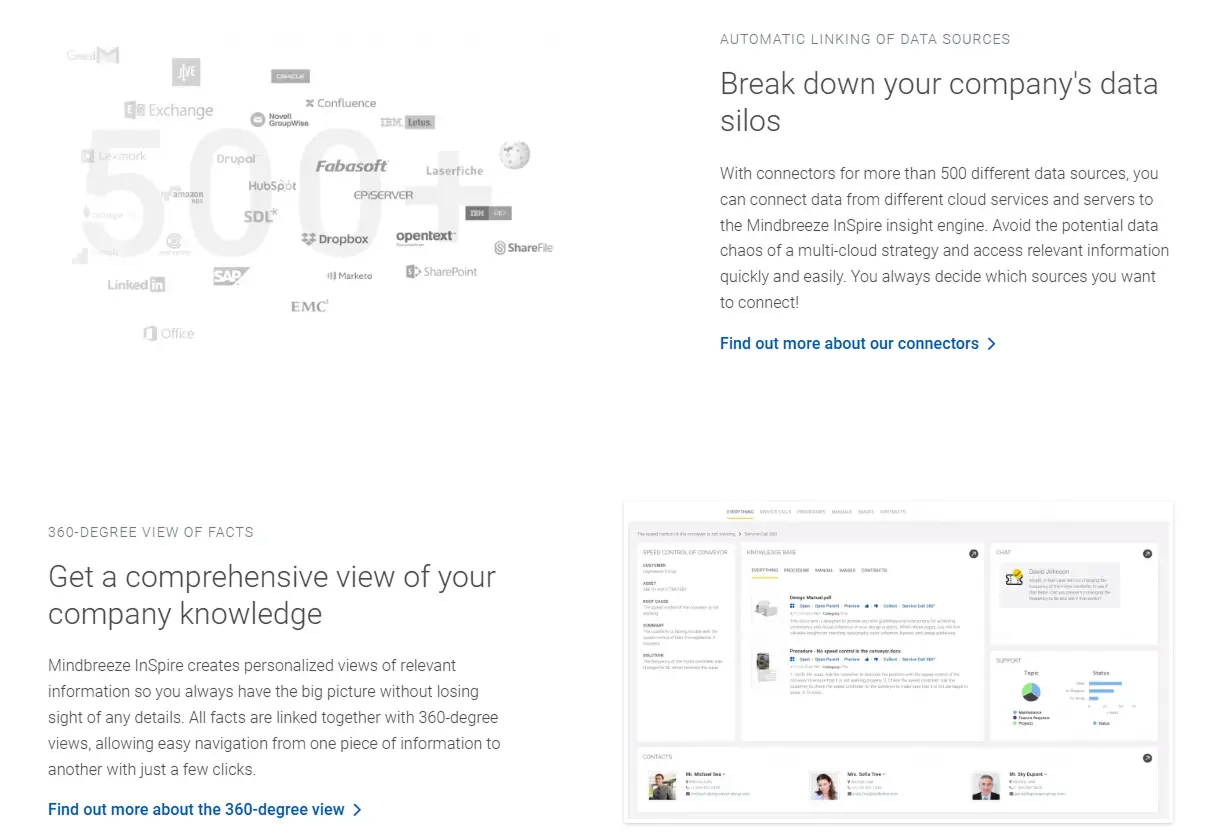 Mindbreeze InSpire is an enterprise insight engine for unstructured and mixed enterprise data. The platform indexes cloud and on-prem repositories, applies semantic enrichment, and delivers AI search, 360-degree knowledge views, and chat-style retrieval with source citations.
Mindbreeze InSpire is an enterprise insight engine for unstructured and mixed enterprise data. The platform indexes cloud and on-prem repositories, applies semantic enrichment, and delivers AI search, 360-degree knowledge views, and chat-style retrieval with source citations.
For regulated or hybrid environments, the core value is controlled retrieval-augmented generation (RAG) over internal data, with role-based access preserved.
Mindbreeze positions InSpire as cloud, hybrid, or on-prem and supports open model choice (GPT, Llama, or customer-provided models). It supports multimodal LLM workflows and integrations with Microsoft 365, SharePoint, Outlook, Salesforce, SAP, OpenText, and Exchange.
Key strengths & specializations
- Strong unstructured data ingestion and federation with 500+ connectors across enterprise content systems.
- Semantic and AI services available across editions, including NLP, entity recognition, classification, semantic relations, knowledge extraction, and RAG.
- Search plus knowledge graph style navigation through 360-degree object views and expert discovery.
- Enterprise-fit architecture, cloud-native plus on-prem options, SDK extensibility, and support for more than 50 languages.
Ideal use case
InSpire fits enterprise search, knowledge management, engineering, support, and operations teams that need trusted retrieval from fragmented document estates.
It fits organizations with mixed stacks (Microsoft, SAP, Salesforce, OpenText, file systems, email archives) and strict data residency or access-control requirements. The strongest outcomes come when teams need answer generation grounded in internal content.
Pricing model
Mindbreeze uses a document-volume model rather than per-seat pricing.
- 1M tier: up to 1,000,000 documents, starts at EUR 83,000 per year (USD 103,700), listed for small organizations.
- 5M tier: up to 5,000,000 documents, price via sales.
- xM tier: more than 10,000,000 documents, price via sales.
- Infinity tier: unlimited documents, price via sales.
Most capabilities are included across tiers, while limits vary by usage volume.
Notable projects
- Mindbreeze enabled a semiconductor equipment manufacturer (1,000 employees, 25+ locations) to complete a 28-day pilot, connect SAP/OpenText/Exchange sources, and roll out intranet 360-degree views for projects, products, and experts by the end of 2023.
- Mindbreeze consolidated maintenance and product data for airline operations, improving proactive maintenance planning and reducing grounding risk through real-time 360 views and interactive BOM navigation.
Customer reviews and considerations
Gartner Peer Insights shows Mindbreeze InSpire at 4.7/5 from 47 ratings. G2 shows 4.4/5 from 11 reviews.
Review themes are consistent: users value search relevance, contextual results, and responsive support.
Common friction points include setup complexity, customization effort, and occasional support bottlenecks for advanced requests.
Coveo AI-Relevance Platform
 Coveo AI-Relevance Platform is an enterprise AI-search layer for unstructured and semi-structured content across websites, support portals, commerce, and workplace systems. It combines semantic search, generative answering, recommendations, and analytics on top of a unified index.
Coveo AI-Relevance Platform is an enterprise AI-search layer for unstructured and semi-structured content across websites, support portals, commerce, and workplace systems. It combines semantic search, generative answering, recommendations, and analytics on top of a unified index.
For organizations with fragmented knowledge, Coveo emphasizes retrieval-grounded AI, relevance tuning, and secure permissions-aware delivery. Core capabilities include unified indexing, query pipeline management, behavioral AI models, document-level permissions, and Passage Retrieval API for RAG and agent workflows.
Key strengths and specializations
- Enterprise search for unstructured data with semantic and hybrid retrieval.
- 100+ connectors and unified indexing for cross-system knowledge access.
- Retrieval-grounded GenAI capabilities including Generative Answering and Passage Retrieval API.
- Relevance optimization via query suggestions, automatic relevance tuning, and analytics.
- Security and compliance controls suited to regulated environments.
Ideal use cases
Best fit is for customer support, ecommerce, and employee knowledge programs that need one relevance layer across many repositories.
Primary beneficiaries include search product owners, knowledge managers, CX teams, and AI platform teams integrating Salesforce, SAP, ServiceNow, Adobe, Sitecore, Shopify, and custom stacks. Typical outcomes are higher self-service success, lower case volume, and better conversion.
Pricing model
Coveo uses contract pricing instead of fully transparent public tiers on its official site.
Pricing is usage-led, primarily by queries and indexed items, and each pricing unit includes 100k queries per month. Generative features are add-ons, and Passage Retrieval API has its own query-unit model. Contracts are usually annual or multi-year.
TrustRadius lists community-reported packaged pricing (Base $600/month, Pro $1,320/month). Treat this as directional and confirm current pricing with Coveo.
Notable projects
- F5 Networks reported +11% self-service success, $450k saved in the first 30 days of generative QA, and +21% uplift in visitors with result clicks after deploying Coveo search and generative answering.
- SAP Concur reported measurable support improvements from Coveo-powered AI, including lower case volume and stronger digital support outcomes in its GenAI program.
Customer reviews and considerations
G2 rates Coveo at 4.3/5 from 143 reviews, and TrustRadius scores it 8.0/10 from 13 reviews.
What customers admire:
- Strong relevance and multi-source indexing.
- Flexible integration and personalization across channels.
Areas to watch:
- Learning curve for advanced tuning and administration.
- Cost and implementation/support expectations on complex deployments.
OpenSearch Project (OpenSearch + OpenSearch Dashboards + Data Prepper)
 OpenSearch Project provides an open-source unstructured data analytics stack with three layers: OpenSearch for indexing and retrieval, OpenSearch Dashboards for analysis, and Data Prepper for ingestion pipelines. The suite supports lexical, semantic, vector, and hybrid retrieval, plus observability workflows for logs, traces, and metrics.
OpenSearch Project provides an open-source unstructured data analytics stack with three layers: OpenSearch for indexing and retrieval, OpenSearch Dashboards for analysis, and Data Prepper for ingestion pipelines. The suite supports lexical, semantic, vector, and hybrid retrieval, plus observability workflows for logs, traces, and metrics.
Data Prepper filters, enriches, normalizes, and routes high-volume events before indexing. This supports RAG pipelines, operational analytics, and cross-signal troubleshooting. Dashboards adds multi-source exploration, query tooling, and workspace isolation.
Key Strengths & Specializations
- Apache 2.0 open-source licensing with plugin extensibility.
- Retrieval coverage across keyword, semantic, vector, and hybrid search.
- Scalable ingestion and transformation via Data Prepper.
- Unified analytics in Dashboards for search, security, and observability.
- Proven scale patterns in enterprise deployments.
Ideal Use Case
Best for platform engineering, data engineering, search engineering, and security/observability teams that need one stack for documents, logs, traces, and mixed telemetry. It fits AWS-heavy environments and self-managed deployments where teams need stronger architecture and governance control.
Pricing Model
OpenSearch Project software is free under Apache 2.0. No project license tiers or token pricing.
Managed deployments follow provider billing. Amazon OpenSearch Service uses pay-as-you-go pricing across instance hours, storage, and data transfer, with On-Demand and Reserved Instance options.
Notable Projects
- Pega reported 60,000+ hours saved annually in management time, 99.95% SLA compliance, and multi-cloud operations after scaling OpenSearch.
- SAP modernized SAP Cloud Logging at 11,000+ instances, unified logs-metrics-traces with OpenTelemetry plus Data Prepper, and created a low-risk path to OpenSearch 2.x.
Customer Reviews and Considerations
Public review coverage for OpenSearch on software review platforms is thin.
On forums users praise fast search and strong AWS integration and managed operations that reduce platform overhead.
As for the points of improvement, users highlight the need for better cost predictability, especially for serverless and low-utilization workloads and easier configuration and clearer integration documentation.
Build the Data Foundations Your Unstructured Analytics Tools Need
The tools in this guide can unlock insights from documents, logs, emails, and other unstructured data, but their performance depends on the quality, structure, and accessibility of the underlying data.
Vodworks’ AI Readiness package helps you prepare your data environment so analytics platforms, search engines, and AI systems can operate reliably at scale.
We help you design quality at the source, make data health traceable, and centralise data from disparate sources in a storage layer of your choice.
Our team begins by assessing your current state of data quality, structure, storage, governance, and compliance. From there, we map a targeted path to a single source of truth and observable, reliable pipelines that can support modern analytics, search, and AI workloads.
Next, we design the data strategy and architecture, implement ingestion, transformation, and enrichment with built-in validation and monitoring, and reinforce it with access controls, audit trails, and policy-as-code governance.
Finally, our engineers operationalise the stack so quality holds up in production and reporting, with MLOps practices applied to maintain reliable models and analytics.
Book a 30-minute discovery call with a Vodworks solution architect to review your data estate and discuss how to prepare it for unstructured data analytics and AI-driven search.

About the Author
Abdul Qayyum
With more than 17 years in software development, Abdul is a Software Architect has extensive expertise in Java, Big Data, AI/ML, and Blockchain technologies. His main role is to deliver strong architecture for back-end and middleware solutions to our clients across diverse business domains, including Telco, E-commerce, Blockchain, Media Streaming, Social Apps, and IoT.


Accelerate Your Projects With Our On-Demand Developers
Let's TalkTalent Shortage Holding You Back? Scale Fast With Us
Frequently Asked Questions
How do you handle different time zones?

With a team of 150+ expert developers situated across 5 Global Development Centers and 10+ countries, we seamlessly navigate diverse timezones. This gives us the flexibility to support clients efficiently, aligning with their unique schedules and preferred work styles. No matter the timezone, we ensure that our services meet the specific needs and expectations of the project, fostering a collaborative and responsive partnership.
What levels of support do you offer?
We provide comprehensive technical assistance for applications, providing Level 2 and Level 3 support. Within our services, we continuously oversee your applications 24/7, establishing alerts and triggers at vulnerable points to promptly resolve emerging issues. Our team of experts assumes responsibility for alarm management, overseas fundamental technical tasks such as server management, and takes an active role in application development to address security fixes within specified SLAs to ensure support for your operations. In addition, we provide flexible warranty periods on the completion of your project, ensuring ongoing support and satisfaction with our delivered solutions.
Who owns the IP of my application code/will I own the source code?
As our client, you retain full ownership of the source code, ensuring that you have the autonomy and control over your intellectual property throughout and beyond the development process.
How do you manage and accommodate change requests in software development?
We seamlessly handle and accommodate change requests in our software development process through our adoption of the Agile methodology. We use flexible approaches that best align with each unique project and the client's working style. With a commitment to adaptability, our dedicated team is structured to be highly flexible, ensuring that change requests are efficiently managed, integrated, and implemented without compromising the quality of deliverables.
What is the estimated timeline for creating a Minimum Viable Product (MVP)?
The timeline for creating a Minimum Viable Product (MVP) can vary significantly depending on the complexity of the product and the specific requirements of the project. In total, the timeline for creating an MVP can range from around 3 to 9 months, including such stages as Planning, Market Research, Design, Development, Testing, Feedback and Launch.
Do you provide Proof of Concepts (PoCs) during software development?
Yes, we offer Proof of Concepts (PoCs) as part of our software development services. With a proven track record of assisting over 70 companies, our team has successfully built PoCs that have secured initial funding of $10Mn+. Our team helps business owners and units validate their idea, rapidly building a solution you can show in hand. From visual to functional prototypes, we help explore new opportunities with confidence.
Are we able to vet the developers before we take them on-board?
When augmenting your team with our developers, you have the ability to meticulously vet candidates before onboarding. We ask clients to provide us with a required developer’s profile with needed skills and tech knowledge to guarantee our staff possess the expertise needed to contribute effectively to your software development projects. You have the flexibility to conduct interviews, and assess both developers’ soft skills and hard skills, ensuring a seamless alignment with your project requirements.
Is on-demand developer availability among your offerings in software development?
We provide you with on-demand engineers whether you need additional resources for ongoing projects or specific expertise, without the overhead or complication of traditional hiring processes within our staff augmentation service.
Do you collaborate with startups for software development projects?
Yes, our expert team collaborates closely with startups, helping them navigate the technical landscape, build scalable and market-ready software, and bring their vision to life.
Our startup software development services & solutions:
- MVP & Rapid POC's
- Investment & Incubation
- Mobile & Web App Development
- Team Augmentation
- Project Rescue
Subscribe to our blog
Related Posts
Get in Touch with us
Thank You!
Thank you for contacting us, we will get back to you as soon as possible.
Our Next Steps
- Our team reaches out to you within one business day
- We begin with an initial conversation to understand your needs
- Our analysts and developers evaluate the scope and propose a path forward
- We initiate the project, working towards successful software delivery