

Inside the AI Data Pipeline: Layers, Guardrails, and Data Readiness

November 24, 2025 - 12 min read

Author

Having AI engineers on your team isn’t enough to develop successful AI systems.
In a global AI craze, companies make a big bet on people with the word “AI” in their title, but the bet doesn’t always play out. According to Glassdoor, “AI engineers” with 4-6 years of experience get on average, a 37% higher compensation compared to regular software engineers. A logical thought would be that “AI engineers” have more relevant experience, however, a successful AI implementation often lies outside of AI engineering responsibilities.
In fact, the latest MIT report states that 75% executives don’t trust AI vendors and consultants because they don’t understand how the company’s data flows work. 65% of surveyed execs don’t trust third-party models if there are no clear data boundaries, such as guardrails for how sensitive data is treated.
These pressing issues often lie in the data engineering area of expertise. The reason why projects that are good on paper, in Jupyter Notebook, or a workflow canvas never reach production is because there’s no reliable AI data pipeline behind them.
By the end of this article you’ll have a better understanding of what AI data pipelines are, how they work, why they are crucial to the success of AI initiatives, and what’s needed to design a robust AI data pipeline in your organisation.
What is an AI data pipeline?
An AI data pipeline is a system that reliably moves data from where it’s generated to where your models can train from it and process it.
At a high level, an AI data pipeline does three things:
- Gets data in: from logs, databases, external APIs, data exports, etc.
- Makes it usable: cleaning, validating, and reshaping it into features the model understands.
- Keeps the flow continuous: the pipeline sends the right data to training and live models in production without delays or downtime.
What is the difference between ETL and AI data pipeline?
At first glance, an AI data pipeline looks a lot like a traditional ETL pipeline. They both move and transform data, and AI data pipeline is a natural progression from ETL. The differences show up in what AI data pipelines are optimised for.
 Final use case
Final use case
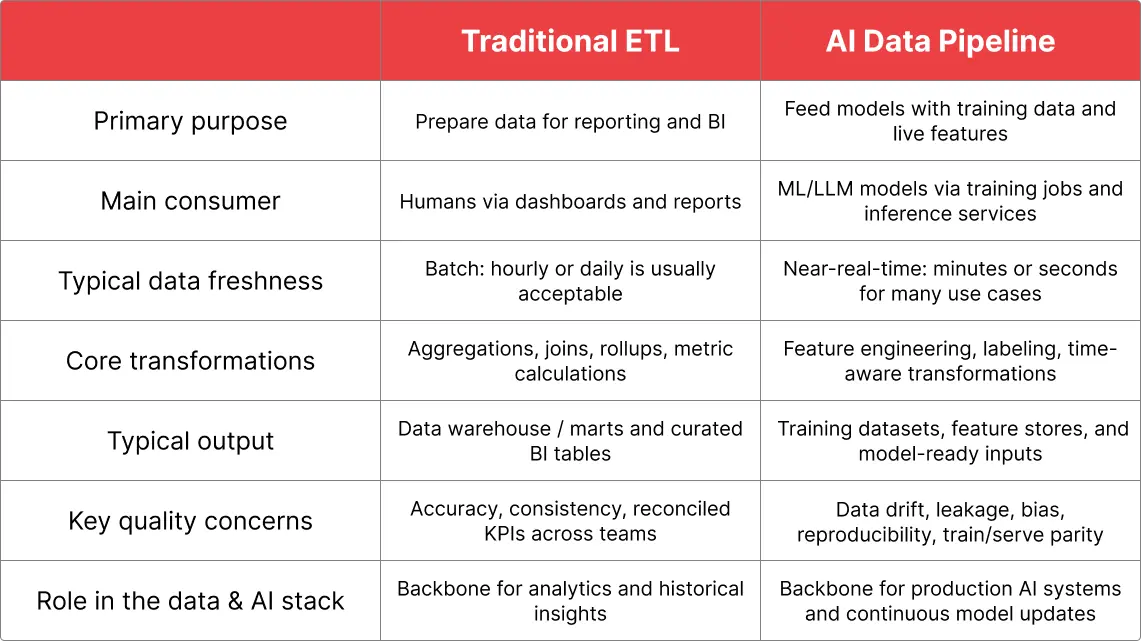
Classical ETL systems are designed for dashboards and real-time reporting, while AI data pipelines are meant to train and serve ML models.
Data refresh rates
In most ETL systems that were built for BI hourly or even daily data freshness was considered to be fine. AI systems often solve real-time problems, like product recommendation or dynamic pricing, where near-real-time data (minutes/seconds precision) is needed. AI data pipelines ensure not only that data is correct, but also that it’s current for this decision.
Data transformation approach
Transformations also differ. For conventional ETL, typical operations would be aggregations, joins, and summaries. The reason for this is that BI transformations are usually about compressing and reshaping data into a form that is easy to aggregate and visualise.
In the case of AI data pipelines the consumer is a model, not a human. That’s why the transformations are designed to create good inputs and targets for learning. This means turning raw data into numerical signals a model can use, labelling raw data for model training, and ensuring that data in production is transformed the same way as during training.
Data quality
ETL and AI data pipelines also have different areas of concern in data quality. For traditional BI systems accuracy and consistency play the key role. This means that the BI system should do correct calculation, have unified business rules for all departments so that every business unit is looking, have an aligned definition of metrics, and BI’s outputs should reconcile with other systems.
For AI, the biggest concern is data drift. If the model was trained on some patterns that radically changed, the model will perform badly. For example, if a model was trained to predict traffic on the website where the major share of traffic was generated by paid ads, and then the company stops running ads, the model will be at a loss and perform badly. BI quality issues are usually noticeable, because charts will look wrong, but AI issues are more silent and result in the model quietly getting worse.
Main Components of the AI Data Pipeline
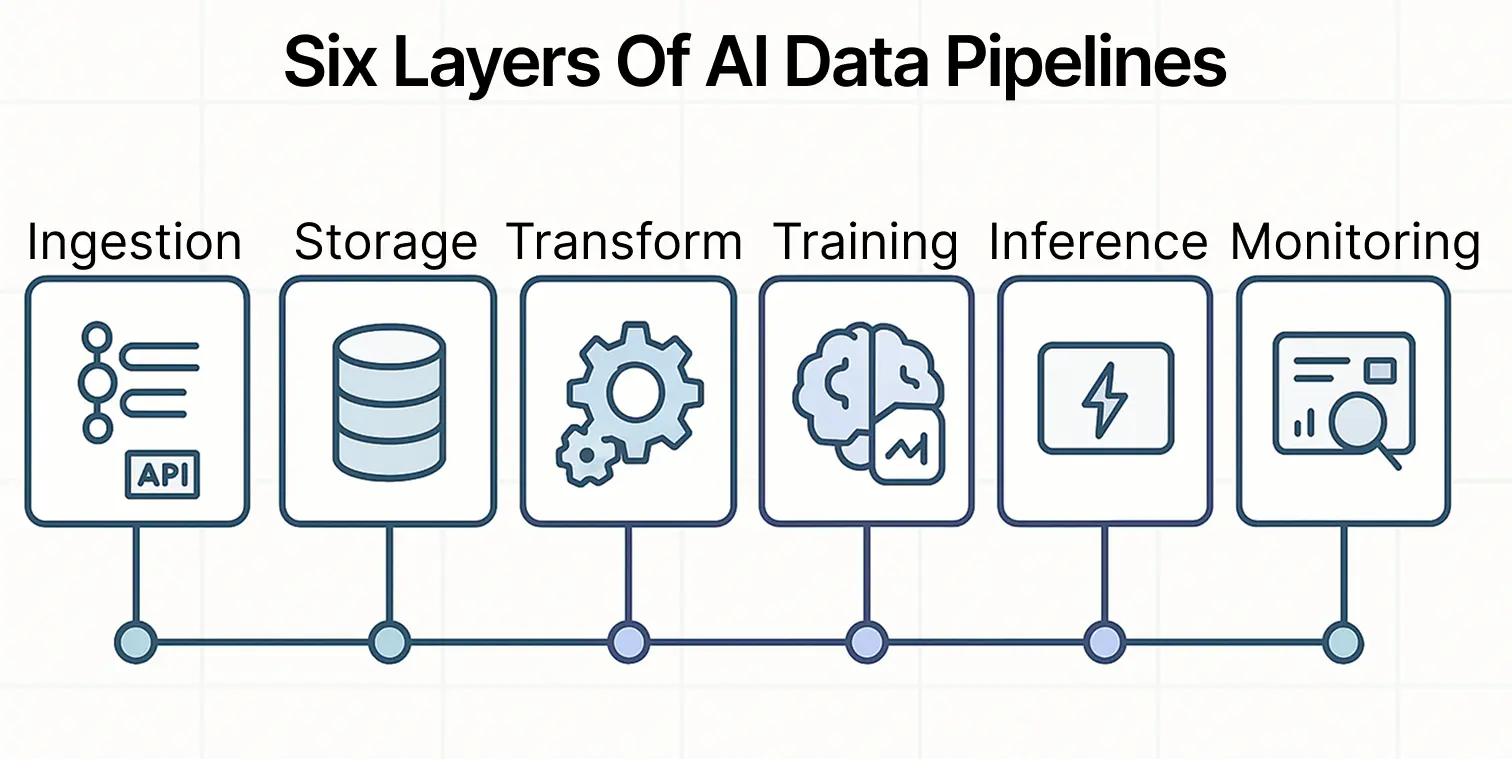
The same as traditional ones, AI data pipelines consist of multiple layers, with each one doing a specific job to feed AI workflows with fresh and reliable data. In this section we’ll take a look at each component, and see how it differs from regular data pipelines.
 Data ingestion layer
Data ingestion layer
AI jobs require a constant stream of data from various sources, depending on the task. This can be event streams, OLTP databases, third-party APIs, and unstructured data sources.
Unlike classical ETL, where data jobs are usually scheduled to fuel certain dashboards or other analytical appliances, AI data pipelines are built with a focus on continuous feed of data.
Storage layer
AI applications are hungry for context, and a lot of that context lives in unstructured data such as images, emails, chats, logs, etc. Until the wide availability of AI this kind of data was mostly indexed for keyword search or archived, while the core business data lived in relational databases and data warehouses as structured tables.
You can learn more about unlocking value from emails, PDFs, and logs in our unstructured data processing explainer.
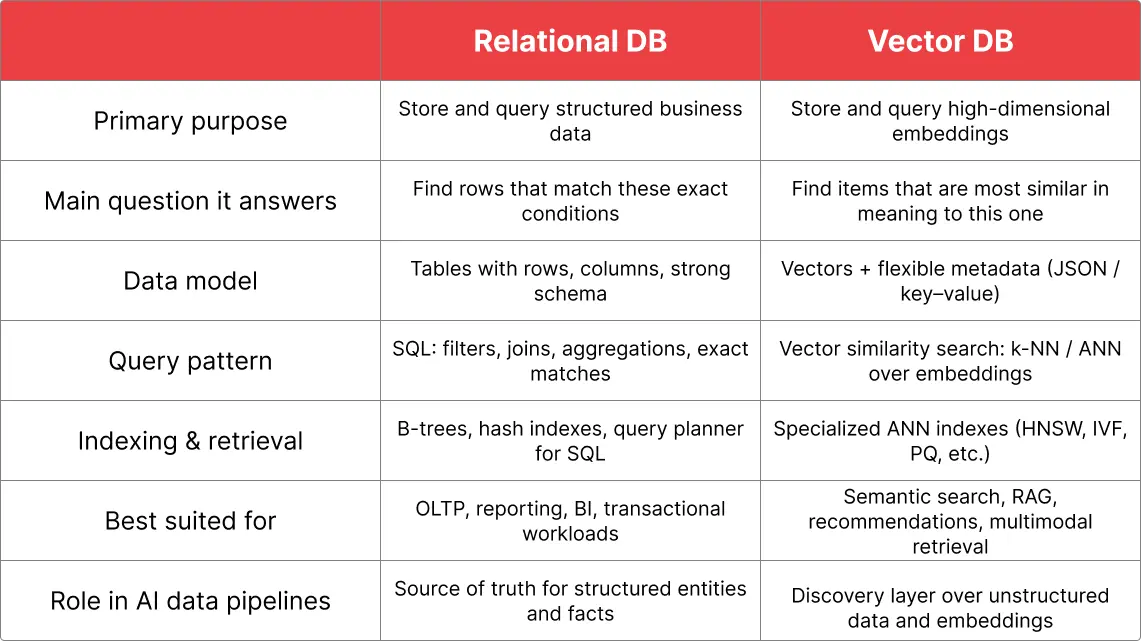
Relational DBs are great for structured, predicate-based queries over tabular data. They’re the right tool when the user knows exactly what they’re looking for. But, they are not designed for semantic similarity, where you ask “find things that mean roughly the same as this.”
Vector databases, on the other hand, are optimised for similarity search over embeddings. They let ML models retrieve information by meaning rather than exact text, and they do it efficiently at scale.
For example, if the same book in a digital library appears under different titles in different languages, a vector database can often find them by semantic similarity, while a relational database will only match the query title if you’ve explicitly stated all alternate names.
In an AI data pipeline’s storage layer, these systems are complementary: relational databases (or warehouses) remain the source of truth for structured business data, while a vector database becomes the discovery layer over unstructured content and embeddings.
 Transformation and processing layer
Transformation and processing layer
In AI data pipelines, the transformation layer is optimised for models, not dashboards. Feature engineering, the process of transforming raw data into valuable features for ML models, is crucial for improving predictive performance, especially when working with tabular data.
Compared to ETL for BI workloads, this kind of transformation leans much more heavily on domain and modeling knowledge. The pipeline not just cleans data and joins tables, it’s deciding which behaviors, time windows, and relationships actually matter for a given prediction task.
Aggregate, pre-summarised tables that work for BI are usually poor inputs for LLMs. They ignore signals such as sequence of events and exact timings, and often mix data from different periods into a single number. That’s great for a monthly revenue chart, but dangerous for modeling because it can hide patterns and even introduce future information into past rows.
Models need time-aware features that reflect what was known at decision time, not just the final metric that was made for the dashboard.
Training layer
The training layer is where all the effort from previous steps finally turns into a model. It takes features and labels from the previous layers and assembles them into well-defined training datasets with specific time ranges, entities, feature versions, and label logic.
This layer also handles experimentation and reproducibility. Different model architectures, hyperparameters, feature sets, or label definitions can be tried against the same dataset, and each run is tracked together with the code version and configuration that produced it.
Inference layer
Once a model has been trained and approved, the inference layer is responsible for turning it into a usable service. This layer takes a versioned model artifact from the training/registry side and exposes it through an interface that other systems can call: a real-time API for online predictions, a batch job for scoring large datasets, or a streaming consumer that reacts to events.
In practice, the inference layer includes model servers, feature or context retrieval logic (e.g. from a feature store, cache, or vector database), and the integration with the product surface: recommendation endpoints, fraud checks in a payments flow, ranking in search, or a RAG endpoint behind a chatbot.
Unlike classic data workflows, where the stage last mile is usually an analytics tool, the deployment layer in an AI pipeline sits directly in the critical path of applications. Its output is an immediate decision or response that affects user experience and business logic in real time, which is why it’s tightly coupled with monitoring, rollback mechanisms, and the rest of your production infrastructure.
Observability layer
The final layer in the AI data pipeline tracks data quality, model performance, uptime, and other health metrics across the entire pipeline. The observability layer enables engineers to identify and solve issues before they impact decisions or skewed AI outputs go to production.
Potential Risks of AI Data Pipelines
Despite data pipelines for AI being more advanced than regular ones, they also introduce more risk.
The main risk is that there’s less visibility into what’s happening after the data heads from the storage to transformation and beyond. LLMs are kinda blackboxes, making it problematic to debug the workflow if something goes wrong.
For example, with BI workflows you can see the whole lifecycle of data, from ingestion to the actual BI system. When AI comes into picture, it’s harder to understand what happens at training or inference stages. That’s why the observability layer is crucial to the efficiency of the entire pipeline.
Another risk is cost. With conventional data pipelines can be set up entirely with free, open source tools. Your main expense will be storage. With LLMs you either need to pay for API calls or rent GPU clusters if you want to self-host your models. Considering that AI can be involved on multiple stages of the pipeline and some workflows can be pretty heavy, costs can add up quickly if you don’t follow your usage closely.
Safety and Security of AI Data Pipelines
 As we mentioned at the start of the post many teams are still cautious about putting AI into production because there are no guardrails on how sensitive data is treated.
As we mentioned at the start of the post many teams are still cautious about putting AI into production because there are no guardrails on how sensitive data is treated.
Those are valid concerns as every stage that touches user input, internal data, or model outputs is now a potential vulnerability. To keep those vulnerabilities manageable, AI teams increasingly rely on guardrails: rule-based and model-based checks that sit around the pipeline and block unsafe behavior.
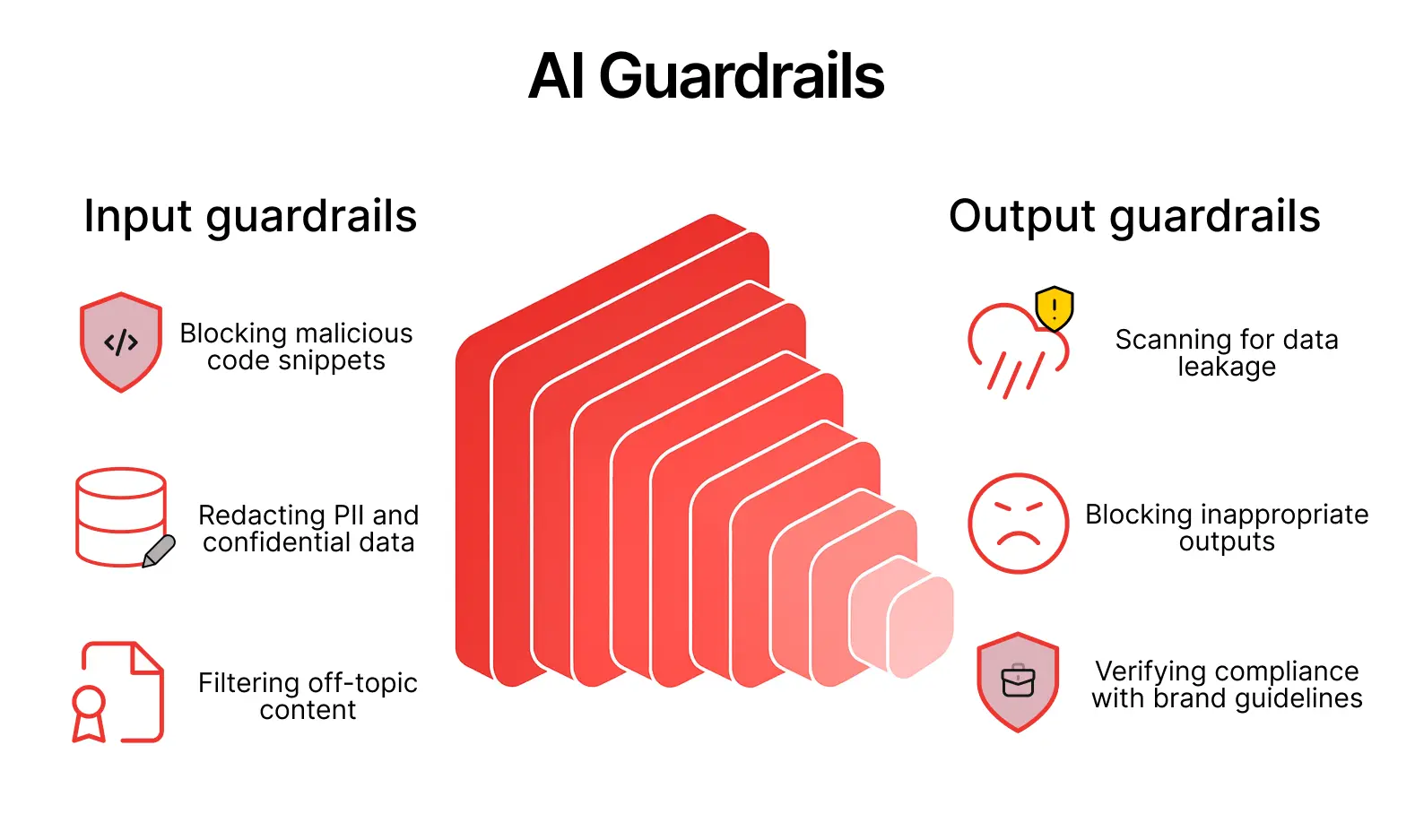
In the context of AI data pipelines, guardrails show up in two places: on the way in and on the way out.
For pipelines that ingest user-generated or otherwise untrusted content (support tickets, logs, chats, uploaded documents, feedback), guardrails can enforce basic policies such as blocking code snippets (to avoid potential attacks), redacting PII or confidential data, and keeping the dataset on-topic instead of absorbing everything that hits the ingestion layer.
On the output side, guardrails act as a final filter over what leaves the system. Before model predictions, generated text, or other artifacts are surfaced externally, they can be scanned for data leakage, inappropriate content, hallucinations, and violations of brand or regulatory guidelines. If an output violates one of these policies, the pipeline can:
- Regenerate the response
- Redact sensitive data
- Escalate to a human reviewer
Speed lies at the core of guardrails like these. In live traffic there’s no room for heavy, multi-stage analysis that adds latency, so guardrails are designed to make fast, mostly binary decisions such as “is this content safe enough to send or not?”. Anything that gets blocked can then be logged, reviewed, and handled by slower, more thorough processes, while the vast majority of safe requests flow through with minimal overhead.
Data Management: an Essential Prerequisite to a Reliable AI Data Pipeline
Models’ accuracy directly depends on the quality of data that’s coming into the pipeline. Even though the transformation layer can cut off obviously incorrect data, such as null values or entries with misaligned data format, it’s not so straightforward with biased datasets or unstructured data.
A well-thought data management framework helps teams move beyond cleaning on the fly and define clear rules around data quality, ownership, governance, lineage, and observability, so that junk data and blind spots are caught before they enter the pipeline.
Instead of guessing whether the data estate is good enough, it’s much safer to score it systematically across a few core pillars:
- How easily people can find and trust data
- How reliably pipelines land and integrate data
- How quality and timeliness are actually measured
- How strong governance and compliance controls are
A structured framework turns data readiness from a vague concept into a concrete checklist that shows where you stand today and which fixes will unlock better AI outcomes tomorrow.
How to Build and Scale your AI Data Pipeline
The fastest way to start with AI data pipelines is to pick one narrow, valuable use case and build a very small, end-to-end flow for it. The approach should be iterative: trying to design a full-scale data platform on day one is usually overwhelming and far more than you need when you’re just getting started with AI.
Take data you already have in a warehouse or production database, define a simple training dataset, train a basic model, and wire it into a single decision or workflow (for example, a churn score, a lead score, or a content recommendation). At this stage, it’s absolutely fine if your AI data pipeline looks like this:
- A scheduled script to extract data
- A notebook or training job
- A model file
- A simple API or batch scoring job
This kind of simple setup, with a low barrier to entry, requires fewer resources to build and leaves more room for experimentation and learning.
Once you’ve proven that the use case works, you can start turning this one-off into a repeatable pipeline. Wrap your ingestion, data prep, and training layers into jobs orchestrated by something like Airflow / Dagster / Prefect.
Read this article to find the right data pipeline tool for your use case.
Store datasets in consistent locations and add basic checks, such as row counts, schema validation, and simple data-quality checks. For RAG-style use cases, this might mean moving from ad-hoc embedding calls to a proper vector database, adding a small ingestion job to keep the index fresh, and logging inputs/outputs so you can see how the system behaves over time.
To take your pipelines to the next level, you’ll need clear policies, ownership, and SLAs on top of the technical pieces. Ask the following questions:
- Who fixes the pipeline when it breaks during off-hours?
- Across business units which data is used in the pipeline who owns the data in that unit?
- Who uses the output of the pipeline?
- What are the SLAs for the uptime and repair times? How are they enforced?
Maintaining a pipeline is a cross-functional task that involves engineers, domain experts, analysts, and data stewards. But if you start small and demonstrate the value of the pipeline it becomes easier to get stakeholder buy-in and secure resources you need to run your pipelines reliably in the long term.
Design a Reliable AI Data Pipeline with Vodworks’ Data & AI Readiness Package
Now that you’ve seen what goes into an AI data pipeline, the next step is turning that picture into a concrete roadmap.
That’s what the Vodworks Data & AI Readiness Package is designed to do. We start with a Use-Case Exploration sprint that validates AI initiatives against business value, data availability, and expected payback. By the end of this workshop, you’ll have a prioritised list of AI pipeline use cases sised for ROI and an initial view of how your ingestion, transformation, training, and inference layers should fit together.
Next, our architects go deep on data readiness and pipeline robustness. We look at data quality, observability, security and guardrails, infrastructure constraints, and organisational readiness for running AI in production.
You’ll receive a data readiness report, an end-to-end AI pipeline/infrastructure map, and an organisational assessment that makes it clear where friction hides today, which risks are most pressing (drift, cost, safety), and what it will actually take to run reliable AI data pipelines in your environment.
If you prefer hands-on delivery, the same specialists can help you clean and organise data, modernise existing pipelines, and operationalise models—so your first production AI use case ships on time, with the right guardrails in place, and with ROI that’s visible in your dashboards rather than just in a notebook.
Book a 30-minute discovery call with a Vodworks solution architect to discuss your use case and data estate for the AI data pipeline.

About the Author
Abdul Qayyum
With more than 17 years in software development, Abdul is a Software Architect has extensive expertise in Java, Big Data, AI/ML, and Blockchain technologies. His main role is to deliver strong architecture for back-end and middleware solutions to our clients across diverse business domains, including Telco, E-commerce, Blockchain, Media Streaming, Social Apps, and IoT.


Accelerate Your Projects With Our On-Demand Developers
Let's TalkTalent Shortage Holding You Back? Scale Fast With Us
Frequently Asked Questions
In what industries can Web3 technology be implemented?

Web3 technology finds applications across various industries. In Retail marketing Web3 can help create engaging experiences with interactive gamification and collaborative loyalty. Within improving online streaming security Web3 technologies help safeguard content with digital subscription rights, control access, and provide global reach. Web3 Gaming is another direction of using this technology to reshape in-game interactions, monetize with tradable assets, and foster active participation in the gaming community. These are just some examples of where web3 technology makes sense however there will of course be use cases where it doesn’t. Contact us to learn more.
How do you handle different time zones?
With a team of 150+ expert developers situated across 5 Global Development Centers and 10+ countries, we seamlessly navigate diverse timezones. This gives us the flexibility to support clients efficiently, aligning with their unique schedules and preferred work styles. No matter the timezone, we ensure that our services meet the specific needs and expectations of the project, fostering a collaborative and responsive partnership.
What levels of support do you offer?
We provide comprehensive technical assistance for applications, providing Level 2 and Level 3 support. Within our services, we continuously oversee your applications 24/7, establishing alerts and triggers at vulnerable points to promptly resolve emerging issues. Our team of experts assumes responsibility for alarm management, overseas fundamental technical tasks such as server management, and takes an active role in application development to address security fixes within specified SLAs to ensure support for your operations. In addition, we provide flexible warranty periods on the completion of your project, ensuring ongoing support and satisfaction with our delivered solutions.
Who owns the IP of my application code/will I own the source code?
As our client, you retain full ownership of the source code, ensuring that you have the autonomy and control over your intellectual property throughout and beyond the development process.
How do you manage and accommodate change requests in software development?
We seamlessly handle and accommodate change requests in our software development process through our adoption of the Agile methodology. We use flexible approaches that best align with each unique project and the client's working style. With a commitment to adaptability, our dedicated team is structured to be highly flexible, ensuring that change requests are efficiently managed, integrated, and implemented without compromising the quality of deliverables.
What is the estimated timeline for creating a Minimum Viable Product (MVP)?
The timeline for creating a Minimum Viable Product (MVP) can vary significantly depending on the complexity of the product and the specific requirements of the project. In total, the timeline for creating an MVP can range from around 3 to 9 months, including such stages as Planning, Market Research, Design, Development, Testing, Feedback and Launch.
Do you provide Proof of Concepts (PoCs) during software development?
Yes, we offer Proof of Concepts (PoCs) as part of our software development services. With a proven track record of assisting over 70 companies, our team has successfully built PoCs that have secured initial funding of $10Mn+. Our team helps business owners and units validate their idea, rapidly building a solution you can show in hand. From visual to functional prototypes, we help explore new opportunities with confidence.
Are we able to vet the developers before we take them on-board?
When augmenting your team with our developers, you have the ability to meticulously vet candidates before onboarding. We ask clients to provide us with a required developer’s profile with needed skills and tech knowledge to guarantee our staff possess the expertise needed to contribute effectively to your software development projects. You have the flexibility to conduct interviews, and assess both developers’ soft skills and hard skills, ensuring a seamless alignment with your project requirements.
Is on-demand developer availability among your offerings in software development?
We provide you with on-demand engineers whether you need additional resources for ongoing projects or specific expertise, without the overhead or complication of traditional hiring processes within our staff augmentation service.
Do you collaborate with startups for software development projects?
Yes, our expert team collaborates closely with startups, helping them navigate the technical landscape, build scalable and market-ready software, and bring their vision to life.
Our startup software development services & solutions:
- MVP & Rapid POC's
- Investment & Incubation
- Mobile & Web App Development
- Team Augmentation
- Project Rescue
Subscribe to our blog
Related Posts
Get in Touch with us
Thank You!
Thank you for contacting us, we will get back to you as soon as possible.
Our Next Steps
- Our team reaches out to you within one business day
- We begin with an initial conversation to understand your needs
- Our analysts and developers evaluate the scope and propose a path forward
- We initiate the project, working towards successful software delivery