

The Ultimate List of Data Pipeline Tools for 2025

October 17, 2025 - 15 min read

Author

Data pipeline tools are the backbone of modern analytics, enabling you to reliably move and transform data from source to destination for real-time insights. In an era where data volumes are soaring and data itself becomes a driving force of AI, the data pipeline tools market is projected to grow from $12.09 billion in 2024 to $48.33 billion by 2030 (26% CAGR).
Choosing the right tool can make or break your data strategy. Below, we explore the leading data pipeline tools, each with a full profile of what they do, where they excel, and how they fit into your business.
1. Apache Airflow by Apache Software Foundation
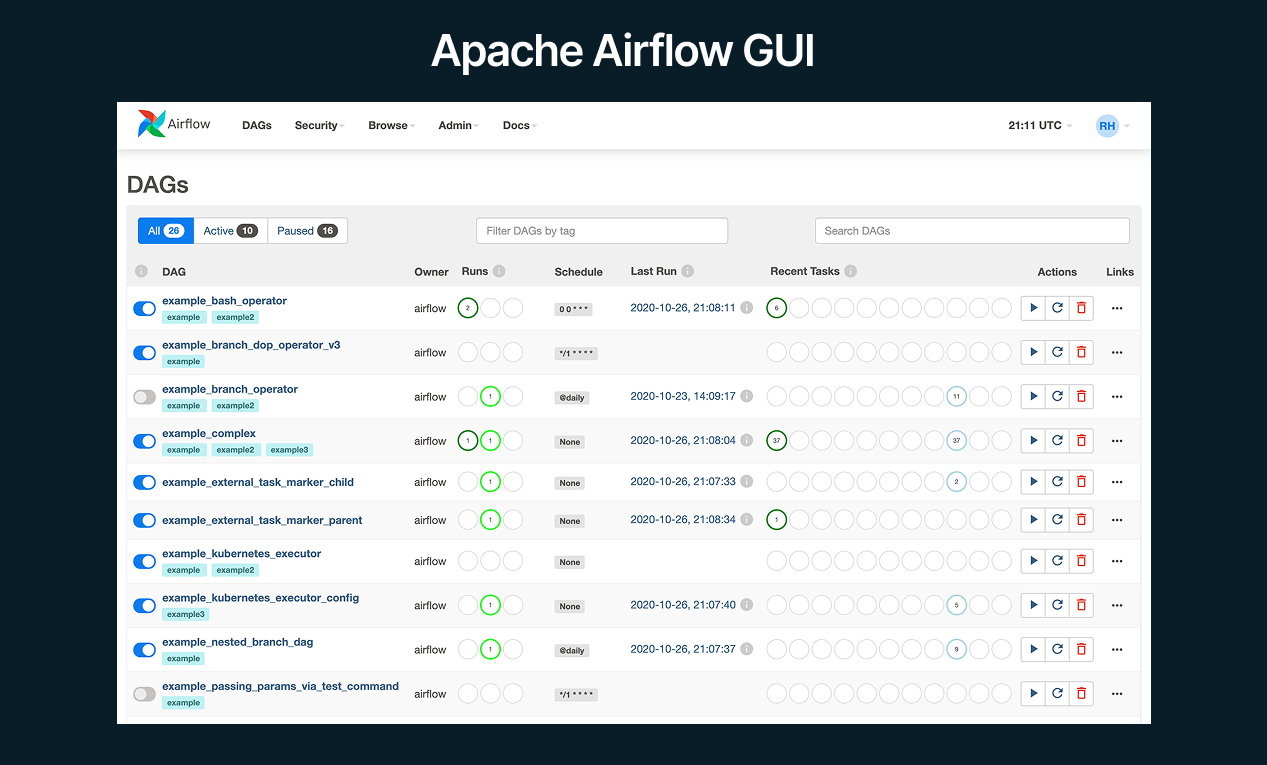
Apache Airflow is an open-source workflow orchestration platform designed to programmatically author, schedule, and monitor data pipelines. This data pipeline tool lets you define complex DAGs (Directed Acyclic Graphs) of tasks in Python code, making it highly extensible for custom workflows.
 Airflow’s scheduler executes tasks on an array of workers, ensuring data workflows run in the correct order and retry on failure.
Airflow’s scheduler executes tasks on an array of workers, ensuring data workflows run in the correct order and retry on failure.
It’s deployment-agnostic: you can self-host it on-premises or run it in the cloud (e.g. via managed services like AWS MWAA or Google Cloud Composer).
In modern data stacks, Apache Airflow has become the industry’s de-facto standard for pipelines as code. It’s popular among enterprises and startups alike for its “configuration as code” approach.
Key Strengths:
- Code-Based Orchestration: Define pipelines in Python for ultimate flexibility; ideal for complex dependencies and custom logic.
- Scalability & Reliability: Proven to handle thousands of daily workflows with a robust scheduler and distributed execution.
- Extensible Ecosystem: Hundreds of provider plugins to integrate with cloud platforms (AWS, GCP, Azure), databases, SaaS APIs, and more.
- Strong Community Support: Airflow has communities across multiple platforms (Github discussions, Slack channel) where users can get help and exchange best practices.
- Cloud & On-Prem Options: Available as open-source (self-managed) or via managed services (Astronomer, Cloud Composer, etc.), fitting both startups and large enterprises.
Ideal Use Case
Airflow is ideal for data engineering teams who need highly customizable, Python-native pipeline orchestration across varied systems.
If you’re automating batch workflows, Airflow provides the flexibility and control you want. It works best in mature analytics setups, for example, a mid-to-large enterprise coordinating multi-step transformations across multiple data warehouses and ensuring downstream BI reports update reliably.
According to Airflow data engineering survey, three most often use cases for the tool are:
- 85.5% use Airflow to manage ETL/ELT workflows.
- 23.1% use Airflow for ML training and pipeline orchestration.
- 8.9% use it for GenAI use cases.
In short, if you need to coordinate diverse tools into one coherent workflow, Airflow is often the go-to solution.
Limitations
Despite its power, Airflow comes with a steep learning curve for newcomers. Some users report that when working with complex workflows, Airflow might take months to master.
Engineers must be comfortable with Python and the DAG concept, which means initial onboarding and workflow development can be time-consuming.
Some users also cite the web UI as dated and less intuitive, although it’s improved in recent versions. Lastly, while Airflow can scale, very large deployments may need careful tuning of the scheduler and executors to avoid bottlenecks.
Pricing Model
Apache Airflow is open-source and free to use under the Apache License. You can run it on your own servers or cloud instances without licensing costs.
Integrations and Ecosystem
Airflow’s ecosystem supports 80 out-of-the-box connectors.
It includes connectors (operators and hooks) for all major cloud platforms – AWS (S3, Redshift, EMR, etc.), Google Cloud (BigQuery, GCS), Microsoft Azure – as well as databases (MySQL, Postgres, Snowflake), analytics tools, and even REST APIs.
Airflow’s plugin architecture allows you to extend it to any system (123 providers). This means Airflow can sit at the center of your data stack, orchestrating tasks across different services seamlessly.
Additionally, Airflow supports API integration and programmatic pipeline generation – you can embed Airflow in CI/CD processes or trigger DAGs via REST API.
Customer Reviews and Considerations
Apache Airflow holds an average rating of 4.4/5 on G2, with users praising its flexibility, scalability, and strong orchestration capabilities for complex data workflows.
For potential users, key considerations include:
- Airflow’s technical complexity and learning curve may not suit small teams or organizations seeking simple, plug-and-play workflow tools.
- Its setup and maintenance requirements can demand significant DevOps expertise.
- While highly configurable, Airflow’s user interface and documentation are sometimes seen as less intuitive compared to newer managed platforms.
Verdict
Best for teams needing highly customizable orchestration in a Python-centric environment. If you require an “infra-as-code” approach to complex data pipelines and value the flexibility to integrate with any tool, Airflow is your strategic choice for data pipeline orchestration.
Talk to our data architects to design a scalable orchestration layer and see where Airflow fits best in your modern data stack.
2. Apache Kafka by Apache Software Foundation
Apache Kafka is an open-source distributed event streaming platform used to build real-time data pipelines and streaming applications.
At its core, Kafka is a publish-subscribe messaging system that can ingest and deliver trillions of messages per day with minimal latency.
In a data pipeline context, Kafka often serves as the central data backbone – it streams events (logs, transactions, sensor readings, etc.) from source systems and buffers them for consumers that process the data in real time.
Kafka is a popular choice for high-throughput, low-latency data integration, enabling use cases like streaming ETL, log aggregation, and event-driven microservices.
In modern data stacks, Kafka fits wherever real-time or asynchronous data movement is needed. It’s frequently deployed in cloud environments and on-premises alike, forming the heart of streaming architectures (often alongside Kafka Connect for source/sink integration and Kafka Streams or Flink for processing).
Kafka’s adoption is massive, it is trusted by** 80 out of Fortune 100 companies** for mission-critical streaming pipelines.
Key Strengths:
- High-Throughput Streaming: Kafka can handle extremely large volumes of data with low latency (clusters can achieve network-limited throughput and latencies as low as 2ms). It excels at real-time feeds and event ingestion.
- Scalability & Fault Tolerance: Architected to scale horizontally to hundreds of brokers, Kafka can process trillions of events per day without downtime. Built-in replication and failover ensure data durability and high availability.
- Rich Ecosystem (Connect & Streams): Kafka Connect offers pre-built connectors to integrate with databases, cloud storages (S3, GCS), search indexes, and more. Kafka Streams (and ksqlDB) enable in-stream transformations and aggregations with ease.
- Wide Language Support: Client libraries exist for Java, Python, Go, .NET, and more, allowing diverse teams to produce/consume events in their preferred language. This makes Kafka a universal data bus connecting heterogeneous systems.
Ideal Use Case
Apache Kafka is ideal for organizations that need to move data in real time and integrate systems via event streams.
Common scenarios include: an e-commerce company streaming clickstream and transaction events for instant analytics, or a bank using Kafka to ingest financial trades and feed risk monitoring systems with sub-second latency.
If your team is building microservices or data products that rely on event-driven architecture, Kafka is often the glue – letting different services publish events and react to them asynchronously.
It’s best for engineering teams in large enterprises or tech-savvy mid-sized firms that require high throughput and guarantee on data delivery (e.g., processing IoT sensor data or user activity logs continuously).
Limitations
Kafka’s power comes with complexity. Operational overhead is a key consideration. Managing a Kafka cluster requires expertise in distributed systems. For smaller teams or low-volume use cases, Kafka can be overkill compared to simpler messaging systems.

The learning curve for Kafka’s internals (broker tuning, partitioning strategy) is non-trivial.
Also, Kafka by itself doesn’t provide data transformation; you often need to pair it with consumers that process data (like Spark/Flink or Kafka Streams).
In terms of cost, Kafka’s throughput assumes use of considerable compute and network resources, so self-hosting at scale can be expensive (hardware-wise).
Lastly, debugging across a distributed Kafka pipeline can be challenging: tracing events end-to-end requires good tooling (which Confluent and others provide at a price).
Pricing Model
Apache Kafka itself is open-source and free.
The real pricing consideration is whether to go with a managed Kafka service or an enterprise distribution.
Confluent Platform, the leading commercial offering for Kafka, uses a subscription model. The platform offers three plans:
- Basic – starts from $0/month
- Standard – starts from $385/month
- Enterprise – starts from $895/month
Plans vary depending on the data storage space and data throughput you need.
Additionally, Kafka Connectors from vendors or premium support can carry license costs.
Integrations and Ecosystem
Kafka’s integration ecosystem is rich, largely thanks to Kafka Connect. There are connectors for many databases (PostgreSQL, Oracle, MongoDB), file systems (e.g., ingest logs from files), and enterprise systems (Salesforce, SAP), enabling Kafka to pull data from or push data to these systems in real-time.
On the Confluent hub, there are 248 connectors for Kafka.
On the BI/analytics end, Kafka can serve as a source for tools like Rockset or ksqlDB for real-time querying. Additionally, many cloud platform services (AWS Kinesis, GCP Pub/Sub) are analogous to Kafka, and Kafka connectors exist to bridge them.
The Kafka API and protocol have become a standard; even if you’re not literally using Kafka, many systems (like Redpanda or Pulsar or Azure Event Hubs) offer Kafka-compatible interfaces.
Customer Reviews and Considerations
Apache Kafka holds an average rating of 4.5/5 on G2, supported by 124 user reviews. G2 Users consistently praise Kafka’s performance, reliability, and suitability for real-time event streaming and integration at scale.
For potential adopters, key considerations include:
- Kafka’s infrastructural and operational demands, including cluster setup, ZooKeeper management (in legacy modes), and tuning can pose challenges, especially for less mature teams.
- While it excels in high-throughput, low-latency environments, Kafka may feel overengineered for simpler messaging or lightweight queueing use cases.
- Also, its user interface, monitoring, and debugging tools are often viewed as less friendly or incomplete, requiring third-party or custom tooling to fill the gaps.
Verdict
Best for real-time data streaming at massive scale. Apache Kafka is the top choice when you need a fault-tolerant, high-throughput pipeline to feed live data across systems, indispensable for large enterprises and tech companies that require instantaneous data flow and processing.
Book a session with our engineers to map out real-time data streaming and integrate Kafka seamlessly into your pipeline architecture.
3. Apache NiFi by Apache Software Foundation
Apache NiFi is an open-source data integration tool focused on automating data flows between systems.
It provides a visual, drag-and-drop interface to design data pipelines (called flows) where data is routed, transformed, and processed through a series of processors. Users drag processors onto a canvas, connect them to form a directed graph, and configure how data should be manipulated at each step.
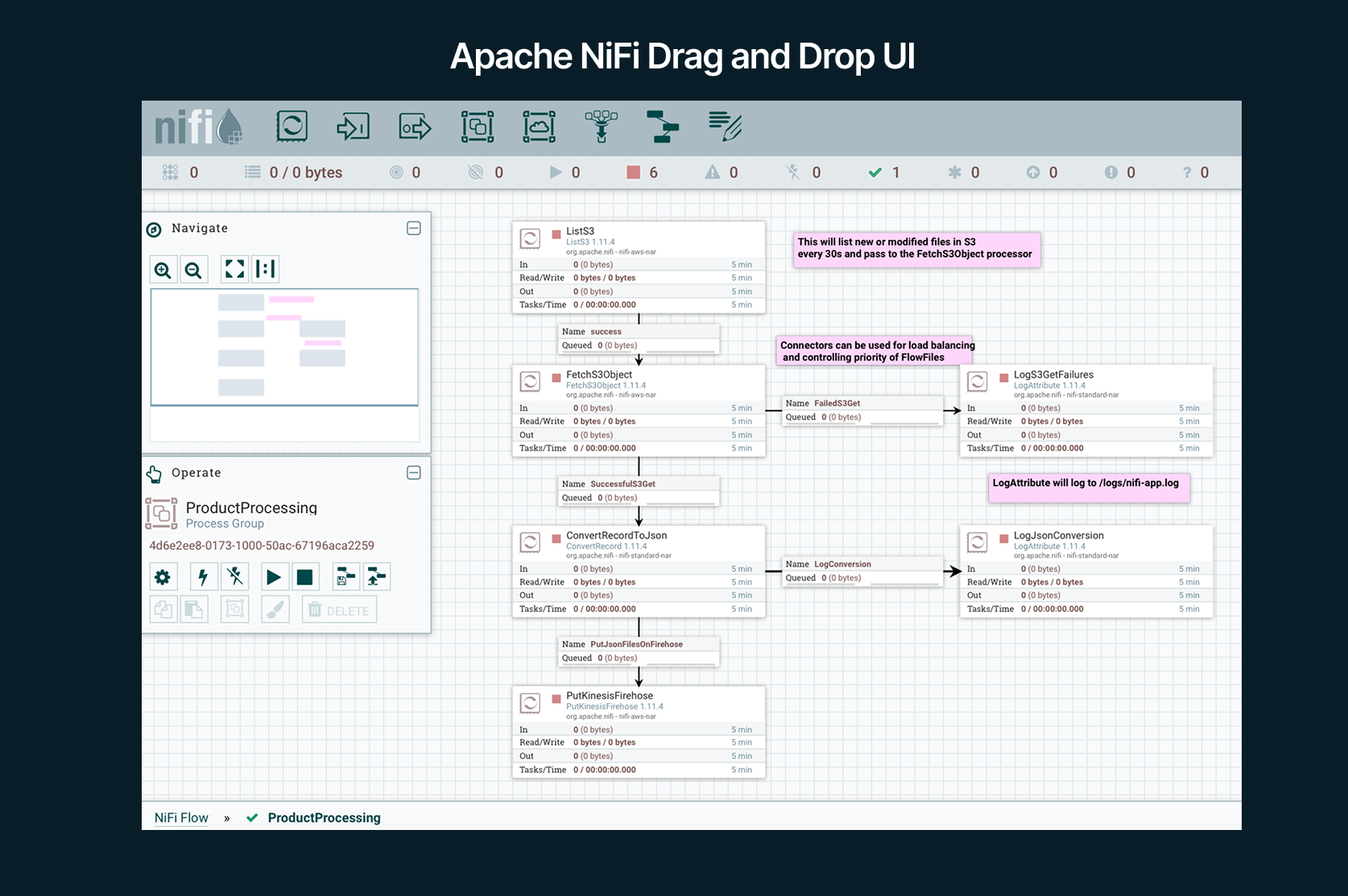 NiFi is designed for real-time, byte-level stream processing as well as batch data movement. It handles sources ranging from files, databases, and message queues to IoT sensors.
NiFi is designed for real-time, byte-level stream processing as well as batch data movement. It handles sources ranging from files, databases, and message queues to IoT sensors.
In modern data stacks, NiFi often serves as a data ingestion and routing layer. It’s deployed by enterprises needing a user-friendly way to gather data from diverse sources and deliver it to various destinations (e.g., ingest logs and stream to HDFS, or capture IoT device readings and push to a database).
Notably, NiFi was born at the NSA (US National Security Agency) and is built with security and robustness in mind for high-volume data flows. Many government, healthcare, and large enterprises use NiFi for its fine-grained control and monitoring of data motion.
Key Strengths:
- No-Code, Visual Pipelines: Easy-to-use web-based UI for designing and monitoring pipelines. Business analysts or data engineers can build flows without writing code, accelerating development.
- Rich Processors & Protocols: NiFi supports an extensive range of data formats and protocols out-of-the-box, from HTTP, FTP, and SFTP to Kafka, MQTT, JDBC, etc. This makes it popular for integrating disparate systems in real-time.
- Data Provenance & Tracking: Built-in provenance logging means every data object can be traced (what transformations applied, where it came from). Crucial for compliance and debugging complex data lineages.
- Guaranteed Delivery & Backpressure: NiFi is highly configurable for reliability – it can guarantee delivery, prioritize flows, apply backpressure when downstream is slow, and auto-retry failures, ensuring robust data movement.
- Secure and Enterprise-Ready: Supports SSL/TLS encryption, in-depth access management, and can run in clustered mode for high availability. NiFi’s secure protocols and role management make it suitable for sensitive data scenarios.
Ideal Use Case
Apache NiFi is ideal for organizations that need to quickly build and manage data flows across many systems with minimal coding. For example, an enterprise IT team might use NiFi to collect logs from various servers, filter and enrich them, then route to both a Hadoop cluster and a SIEM tool in real-time.
NiFi is crucial for tasks where ease of use and visual oversight are paramount, e.g. a government agency aggregating data from legacy databases, mainframes, and cloud APIs, or a healthtech company ingesting healthcare data from numerous hospitals and needing to apply standard transformations.
It’s well-suited for scenarios requiring on-premises deployment and strict security (financial institutions integrating internal systems, etc.). If you want a unified platform to ingest, transform, and distribute streaming data without writing custom code in each step, NiFi is a strong candidate.
Limitations
NiFi’s convenience has some trade-offs. The visual interface, while powerful, can become cumbersome for very complex logic. Large flows with dozens of processors might be harder to maintain or version compared to code-based pipelines.
Also, NiFi runs as a continuously operating service that can be memory-intensive; for extremely high event rates, NiFi might require substantial hardware and fine tuning (versus specialized streaming frameworks like Flink).
Another limitation is that NiFi’s paradigm is inherently stateful on a single node (it does have clustering, but scaling horizontally for one flow isn’t as seamless as, say, adding consumer instances in Kafka).
For cloud-native architectures, NiFi may feel a bit “server-centric” (though it can run in containers). It’s not serverless, and managing NiFi clusters is its own DevOps task.
Pricing Model
Apache NiFi is open-source (Apache License 2.0) and free to use. You can download NiFi and run it on your own hardware without any licensing costs. Thus, pricing is primarily the infrastructure to host NiFi (physical or cloud servers) and the personnel to manage it.
There are, however, commercial variants and support available: Cloudera, for instance, offers Cloudera DataFlow (based on NiFi) as part of its platform, which would come under enterprise licensing.
If you use NiFi via this platform or in managed cloud offerings, you might pay subscription fees for that. But the pure Apache NiFi is cost-free.
Integrations and Ecosystem
NiFi comes with a vast library of processors that integrate with many systems out-of-the-box: relational databases (via JDBC connectors), big data stores (HDFS, Hive, HBase), cloud storage (AWS S3, Azure Blob, GCP Storage), messaging systems (Kafka, JMS, MQTT), and more.
It can also interact with web services (GET/POST to REST APIs, listen on HTTP endpoints).
NiFi’s NiFi Registry component allows versioning of flows and promoting them across environments, which is useful in a DevOps toolchain.
While NiFi doesn’t have “plugins” in the same way as Airflow, you can develop custom processors in Java if needed, extending its capabilities. There is a growing ecosystem of such custom processors shared by the community (for specialized protocols or data formats). For example, here’s a library of custom processors and bundles on Github.
A related Apache project Minifi extends NiFi integrations to edge/IoT devices by providing a small-sized agent that feeds into NiFi.
Overall, NiFi’s ecosystem is strongest in the context of enterprise integration: it plays nicely with data lakes, warehouses, and stream processors, serving as the intake and distribution hub in a larger data platform.
Customer Reviews and Considerations
Apache NiFi holds an average rating of 4.2/5 based on 25 user reviews on G2. Its users often value its intuitive data-flow visual interface, flexible connectivity, and strong capability to orchestrate and route data across systems.
For organizations considering adoption, key considerations include:
- NiFi’s scalability and clustering setup can introduce operational complexity;
- Its stability under heavy or complex workloads is sometimes questioned, especially when handling large tables or stateful transformations.
- While the drag-and-drop, UI-based flow design is praised for ease of use, its support for advanced customization, enterprise features (e.g. SSO, fine-grained access control), and documentation are viewed by users as areas needing improvement.
Verdict
Best for teams needing a secure, real-time data ingestion and routing platform with a visual interface. Apache NiFi stands out for automating complex data flows in real-time, especially in enterprise environments where quick configuration and end-to-end data tracking are paramount.
4. AWS Glue by Amazon Web Services
AWS Glue is a fully managed cloud ETL (Extract, Transform, Load) service provided by Amazon. It simplifies the process of discovering, preparing, and combining data for analytics, machine learning, and application development.
Glue automates much of the heavy lifting in building data pipelines: it can crawl your data sources to infer schema and create a data catalog, generate ETL code (in Python/Scala Spark) to transform and move data, and execute those jobs on a serverless Apache Spark environment. Essentially, AWS Glue provides a platform where you define data sources, targets, and transformation logic, and AWS handles provisioning and scaling the underlying compute resources (you don’t manage servers – it’s serverless). Glue also includes features like AWS Glue Studio (visual interface for building ETL jobs), Glue DataBrew (a data prep UI for analysts), and Glue Streaming for real-time ETL use cases.
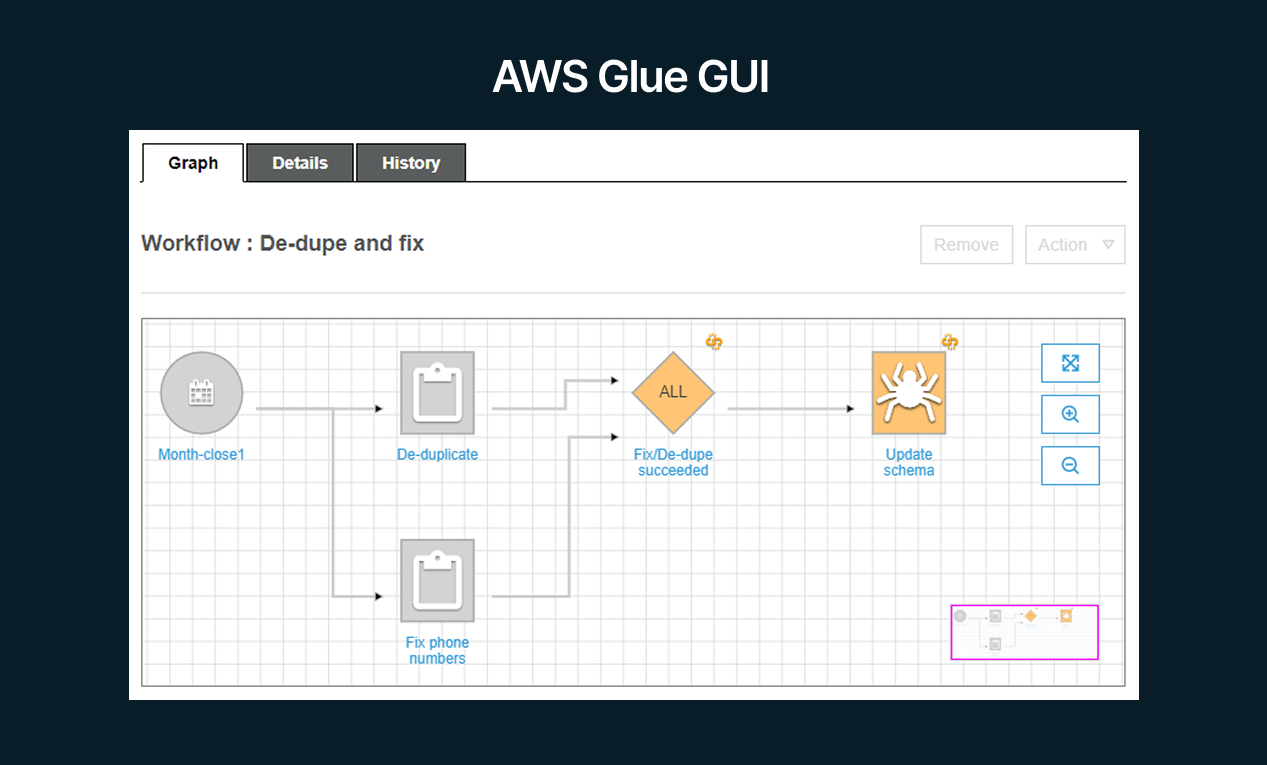
In the modern data stack, AWS Glue fits well for organizations building on AWS who need a native ETL solution. Instead of manually spinning up Apache Spark clusters or writing custom data movement code, teams can use Glue to quickly connect data lakes, data warehouses, and various databases or APIs.
Key Strengths
- Serverless ETL: Completely managed infrastructure – just submit jobs and AWS provisions the necessary Spark compute. It has no clusters to maintain and requires no provisioning or management of servers which accelerates development and lowers ops overhead.
- AWS Ecosystem Integration: Glue integrates seamlessly with AWS data stores (S3, Redshift, RDS, DynamoDB) and analytics services. For example, it can automatically register schemas in the Glue Data Catalog, which Athena and Redshift can query directly. Permissions via IAM are unified.
- Schema Discovery & Catalog: Glue Crawler can scan data in S3 or JDBC sources to infer schema and partition info, populating a centralized Data Catalog. This is great for data lake scenarios where schema discovery is needed.
- Flexible Development Options: Offers both a visual ETL builder (Glue Studio) and code-based development. Developers can write custom PySpark or Scala Spark transformations if needed, while less technical users can use the GUI to map transformations.
- Scalability: Glue can scale out to handle large data volumes by parallelizing on Spark. For streaming, Glue Streaming jobs automatically scale to handle event streams. It’s designed to handle enterprise-scale ETL, and you only pay for resources when jobs run.
Ideal Use Case
AWS Glue is ideal for AWS-centric teams (CTOs, data engineers, analytics teams) that need to build and orchestrate ETL/ELT pipelines without managing infrastructure.
If your data resides in AWS services (like logs in S3, operational data in Aurora or DynamoDB, etc.) and you want to create pipelines to a data warehouse (Redshift, Snowflake on AWS) or feed data to analytics (Athena, EMR), Glue provides a native solution.
A typical use case would be an enterprise data lake on S3: Glue Crawlers catalog new files, Glue ETL jobs transform raw data (joining, filtering, aggregating) into queryable parquet tables, and load results to Redshift or back to S3 for Athena.
Glue is also great for teams with mixed skill sets – it enables analysts to do some data prep via DataBrew, while engineers can fine-tune jobs in code.
Because it’s serverless, it suits organizations that prefer managed services to reduce DevOps effort.
Limitations
The most obvious limitation of AWS Glue is that it is tied to the AWS ecosystem and works best with AWS data sources and targets. Connecting it to external systems may require additional setup or networking configuration.
Versioning is another limitation often mentioned by engineers. S3 versioning alone is not enough for many use cases, so teams have to use third-party tools (and AWS connectors for them) for more advanced version control needs.
Some users also mention performance issues under high loads. When processing tables with 10M+ rows, Glue Spark jobs start to struggle.
Another thing to take into account are costs. Glue isn’t an open-source tool as others on our list, and it can become expensive at scale if not optimized. Long-running ETL jobs or very large memory allocations could rack up costs, and the serverless model means you need to optimize job duration.
Pricing Model
Speaking of costs, AWS Glue uses a pay-as-you-go pricing model. For the ETL jobs, pricing is based on Data Processing Units (DPUs) consumed per hour.
A DPU is a relative measure of compute (under the hood, 1 DPU is a chunk of CPU and memory that Glue allocates). Glue jobs are billed per second, with a 1-minute minimum, based on how many DPUs you use.
For example, a job running on 10 DPUs for 6 minutes would cost 10 6 minutes (per-hour rate/60). As of 2025, the rough cost is around $0.44 per DPU-hour in the US-east region (though rates vary). According to users, 1 DPU can process 2 - 4 GB per minute. To process 1TB of data with 1 DPU, it’ll take between 4 hours and 20 minutes to 8 hours and 32 minutes.
Glue Crawlers (for cataloging) are charged per DPU-hour as well when they run.
Glue DataBrew is priced per DataBrew node-hour and number of datasets processed. The price is $0.48 per DataBrew node-hour.
Glue pricing can also include Glue Catalog storage (the metadata store). It’s free for the first million objects stored and after that threshold, it costs $1 for every 100,000 objects.
As you can see, AWS Glue pricing has many variables (and that’s without including the storage costs!), and might scale quickly without smart cost optimization.
Integrations and Ecosystem
AWS Glue is designed to work hand-in-glove with AWS data services. It integrates with Amazon S3 (both as source and target, with tight integration for data lakes), Amazon Redshift (can load data into Redshift and also integrate with Redshift Spectrum), Amazon RDS/Aurora and many other databases via JDBC, DynamoDB, and even AWS API Gateway or rest endpoints via connectors.
Glue Data Catalog is the same catalog used by Amazon Athena, Redshift Spectrum, and EMR, meaning once Glue catalogs your data, other services can immediately query it – a big plus for ecosystem synergy.
For third-party integrations, Glue provides connectors, for example, there are connectors for Snowflake, MongoDB, Oracle, Salesforce, etc., available through the AWS Marketplace. These allow Glue jobs to pull from or push to those external sources.
Glue also supports using AWS Secrets Manager to store credentials securely for connecting to external systems. Additionally, since Glue runs Spark under the hood, you can leverage Spark libraries within Glue scripts (e.g., use Spark ML or custom Python libraries, though you need to package them).
In terms of orchestration, Glue jobs can be triggered by AWS Step Functions or Amazon EventBridge to fit into larger workflows. Glue can output to AWS EventBridge or SNS for notifications.
For developers, Glue offers APIs and a CLI, so you can integrate it into CI/CD pipelines or trigger jobs programmatically. Overall, Glue’s ecosystem is strongest within AWS – it’s meant to be a central ETL component in an AWS-centric data platform, connecting storage, databases, analytics, and ML services together. It may not have a “plugin community” like some open tools, but AWS continuously adds native integration support for popular data sources (especially through the Marketplace connectors feature).
Customer reviews and considerations
AWS Glue holds an average rating of 4.3/5 across 194 user reviews on G2, with reviewers commending its seamless AWS-service integration, simplified ETL orchestration, and managed infrastructure.
For prospective users, key considerations include:
- Its transformation flexibility is often critiqued: users report that more complex or custom transformations may require writing custom code or workarounds.
- Some also mention feature gaps or limitations (for example, limited support for certain file formats, or missing built-in capabilities) that force additional engineering overhead.
- Finally, while AWS offers strong support, users expecting full commercial SLAs or enterprise support may find that such guarantees require enterprise contracts or add-on support plans.
Verdict
AWS Glue is a great data pipeline tool for AWS-based teams seeking a scalable, managed ETL service that minimizes infrastructure hassle. AWS Glue stands out as the go-to choice for cloud ETL on AWS, enabling you to build reliable data pipelines with Spark power, without needing a Spark cluster or heavy DevOps.
Connect with us to optimise your AWS ecosystem and build cost-efficient, serverless ETL pipelines powered by Glue.
5. Azure Data Factory by Microsoft
Azure Data Factory (ADF) is Microsoft Azure’s cloud-based data integration service that allows you to create, schedule, and orchestrate data pipelines at scale. It is essentially Azure’s equivalent of a managed ETL/ELT tool, enabling data movement and transformation both within the cloud and from on-premises to cloud.
With ADF, you create pipelines composed of Activities (such as copy data, run a stored procedure, execute a data flow, etc.) that can be scheduled or triggered by events.
ADF provides a code-free, visual interface (Azure Data Factory Studio) for building these workflows, as well as a rich JSON-based definition language for those who prefer code.
One of ADF’s powerful features is its Mapping Data Flows – a visually designed data transformation logic that runs on Spark under the hood (in Azure’s Databricks or Synapse Spark environment) without you writing Spark code. ADF also integrates an Integration Runtime which can run in Azure or self-hosted, enabling movement of data from on-premises networks securely.
Azure Data Factory is popular among enterprises that have standardized on Azure and want a native tool to connect various Azure services (Blob Storage, Azure SQL, Cosmos DB, Synapse, etc.) as well as external sources. 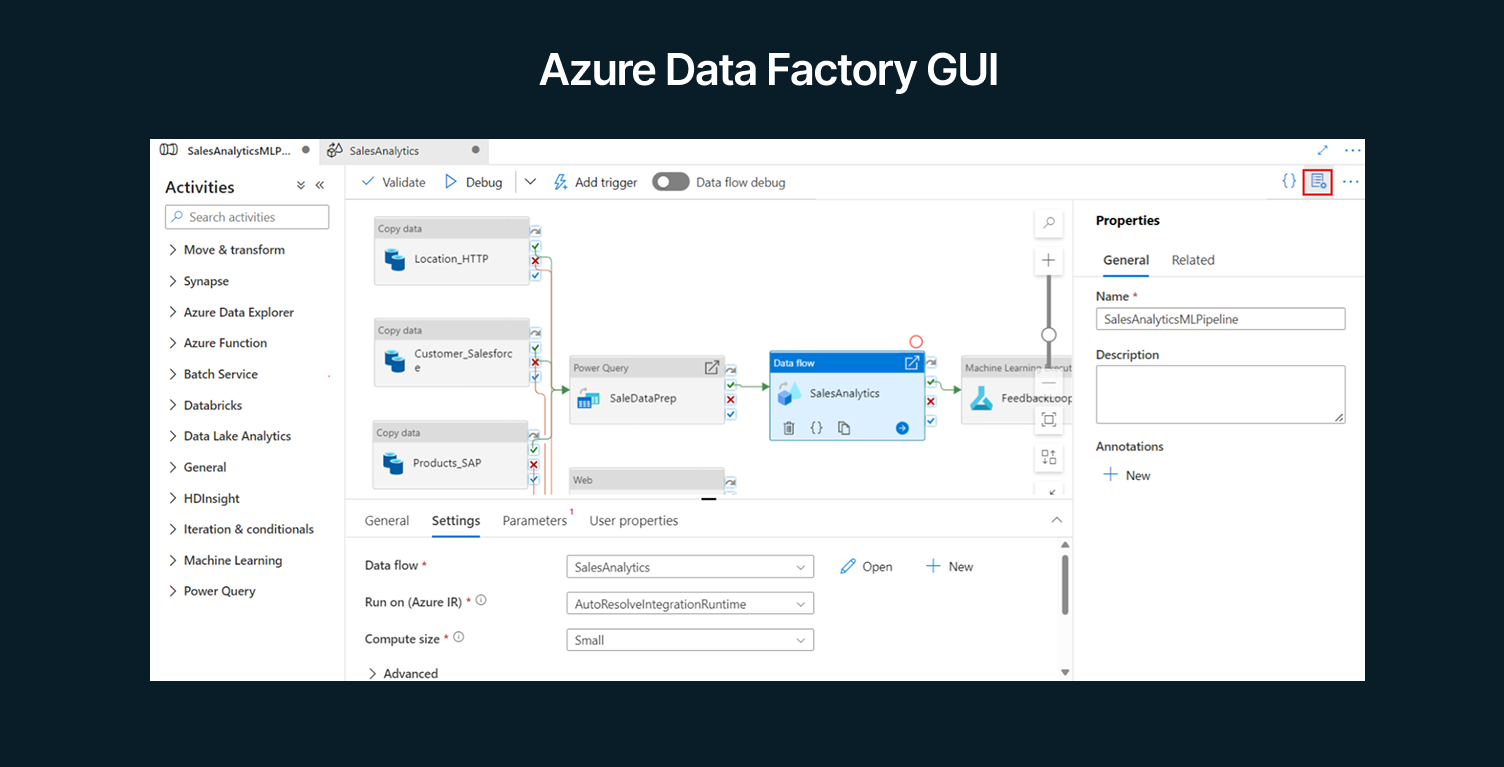 ADF is typically used by both data engineers (to build complex ETL pipelines with branching, loops, dependencies) and by IT integrators for simpler tasks (like nightly copies of data).
ADF is typically used by both data engineers (to build complex ETL pipelines with branching, loops, dependencies) and by IT integrators for simpler tasks (like nightly copies of data).
Key Strengths and Specializations:
- Fully Managed Orchestration: ADF offers a unified way to manage data movement and workflow logic without deploying infrastructure. You get high reliability and scaling out-of-the-box for copy jobs and data flows.
- Broad Connectivity: It provides built-in connectors for 90+ data sources (databases, SaaS, file stores) including on-prem SQL, Oracle, SAP, as well as cloud sources like Amazon S3 – enabling it to act as a central hub for hybrid data.
- Visual ETL: The Mapping Data Flow feature lets you design transformations (joins, aggregates, pivots, etc.) visually, which then execute at scale in Spark. There’s also a Power Query-like interface for data wrangling (great for data prep by analysts).
- Deep Azure Ecosystem Integration: ADF easily triggers Azure Databricks notebooks, Azure Synapse stored procedures, Logic Apps, or Azure Functions. It fits neatly into Azure-based architectures, e.g., you can schedule a Synapse Spark job, then copy results to Blob Storage, then send a completion event – all in one pipeline.
Ideal Use Case
Azure Data Factory is ideal for organizations building on Microsoft Azure that need a versatile data pipeline solution.
Consider a scenario: a global retailer using Azure wants to consolidate sales data from on-prem SQL Server databases, cloud apps like Dynamics 365, and web analytics logs into an Azure Synapse Analytics warehouse for reportingю ADF is tailor-made for this.
It’s best for data engineering teams in mid to large enterprises who require automated, reliable data movement across various sources into Azure.
If you’re already using tools like SQL Server Integration Services (SSIS), ADF is the natural modernization path in the cloud (it can even lift-and-shift SSIS packages into Azure).
Also, for companies adopting a hybrid cloud, ADF is great to incrementally migrate data workloads to Azure while still connecting to on-prem systems. It supports both batch ETL and near-real-time integration (with triggers and event-based pipelines).
Limitations
ADF, with its Platform as a Service model, has some limitations to keep in mind.
Debugging and error visibility can sometimes be challenging. If a Data Flow fails deep in Spark, you might get a somewhat opaque error message.
While ADF’s visual editor is convenient, it may lag or be cumbersome for very large projects with many pipelines; some advanced users prefer provisioning pipelines as code (which is possible through JSON and Azure DevOps YAML, but not as straightforward as purely code-based tools).
Cost can be a factor: each activity in ADF is metered (copy activity is charged by data volume and DIUs used, Data Flow by vCore-hours of Spark, pipeline orchestration by number of run minutes, etc.). For massive data volumes, these costs can add up, and tuning is required to make pipelines efficient.
Another limitation: ADF is primarily an orchestrator and simple transformer – for complex business logic or heavy transformations, you often end up calling external compute (Databricks, Functions, etc.), which adds complexity.
Pricing Model
Azure Data Factory’s pricing is usage-based and a bit complex due to different pipeline activities.
Key components:
Pipeline orchestration is charged per pipeline run and activity run, measured in units of time (1000 pipeline activity runs = $1 in the cloud, or $1.50 with a self-hosted version).
Data movement activities are billed by the volume of data moved, and whether the copy is within the same region or across regions. There’s a concept of DIU (Data Integration Unit) for copy throughput, but effectively you’re charged per hour of copying certain TB of data. Data movement activities cost $0.25 / 1 DIU-hour.
Mapping Data Flows are charged based on the compute used – when you execute a Data Flow, Azure spins up a Spark cluster behind the scenes. You pay per vCore-hour of usage, with a minimum cluster size and execution time (clusters auto-terminate after a job). For instance, a medium Data Flow might use 8 vCores for 10 minutes, you’d pay for that fraction of an hour.
Azure provides its own calculator for a rough estimate depending on the amount of data, number of runs, and other factors.
Integrations and Ecosystem
Azure Data Factory boasts native connectors to a wide array of sources. Within Azure, it connects to Blob Storage, Data Lake Storage, Azure SQL, Synapse, Cosmos DB, Azure Data Explorer, etc.
It also has connectors for external databases (SQL Server, Oracle, DB2, MySQL, etc.), big data systems (HDFS, Hive), SaaS applications (SAP, Salesforce, Office 365, etc.), and generic protocols (HTTP, FTP, REST, OData).
For on-prem connections, the self-hosted integration runtime allows ADF to integrate with internal file systems or databases securely. ADF pipelines can call external compute activities: e.g., it can trigger an Azure Databricks notebook or an HDInsight (Hadoop) job, enabling integration with big data processing outside of the Data Factory itself.
It can also execute Azure Functions or Logic Apps as steps, which means you can extend it to do almost anything (like send an email, perform a complex calculation, etc.).
Customer reviews and considerations
Azure Data Factory holds an average rating of 4.6/5 on G2 (based on 84 user reviews). Users often commend its intuitive interface, strong integration with Azure services, and versatility in handling data pipelines across on-premises and cloud environments.
For potential users, key considerations include:
- Users note that when pipelines become complex, debugging and error handling can become cumbersome, and transformations beyond basic logic may require custom coding or external compute (e.g. Azure Databricks).
- Connectivity with less common or third-party systems (e.g. SAP, certain on-prem platforms) is sometimes seen as limited or error-prone.
- Because ADF is a managed cloud service with pay-as-you-go pricing, cost management is essential, heavy use, frequent pipeline execution, or large data volumes can result in high costs if not carefully monitored.
Verdict
Best for enterprises in the Azure cloud needing a reliable, hybrid data integration platform with both code-free and code-friendly options. Azure Data Factory stands out as the choice for orchestrating and automating data pipelines across the Azure data estate, from on-premises to cloud, with minimal infrastructure worries.
Schedule a consultation to architect Azure-native pipelines that unify your data sources through ADF.
6. Google Cloud Dataflow by Google
Google Cloud Dataflow is a fully managed service for unified stream and batch data processing at scale. It is Google Cloud’s implementation of the Apache Beam programming model, providing a serverless runner that executes Beam pipelines.
In simpler terms, Cloud Dataflow lets developers write a pipeline (in languages like Java or Python using the Beam SDK) that defines data transformations, and then run it on Google’s infrastructure without managing any clusters.
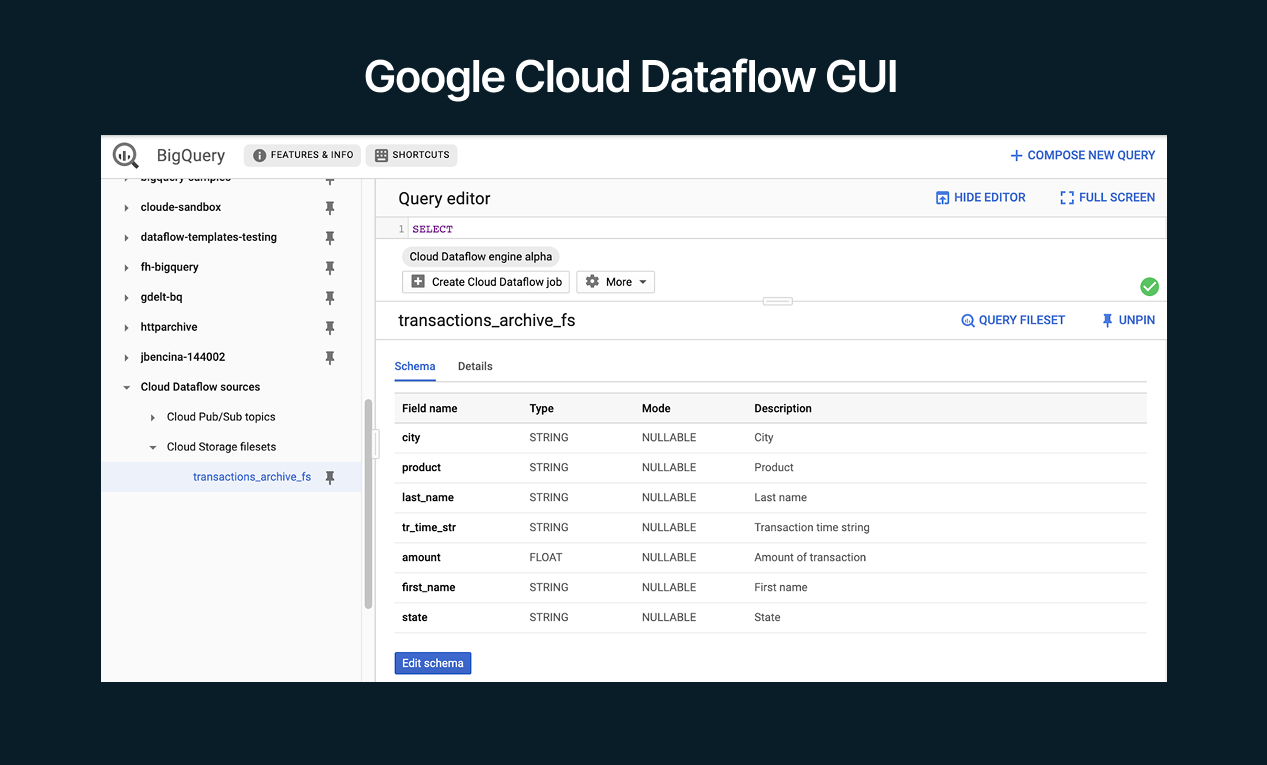 Dataflow is designed for high-throughput, low-latency processing, it can handle both streaming data (continuous, unbounded sources) and batch data, using the same API. Key to Dataflow is its autoscaling and dynamic work rebalancing, which optimize resource usage as the job runs. It’s built on years of Google’s internal tech (successor to MapReduce and Flume/Jupiter). Typical use cases include streaming analytics, ETL, and data pipeline tasks such as enriching or grouping events in real time.
Dataflow is designed for high-throughput, low-latency processing, it can handle both streaming data (continuous, unbounded sources) and batch data, using the same API. Key to Dataflow is its autoscaling and dynamic work rebalancing, which optimize resource usage as the job runs. It’s built on years of Google’s internal tech (successor to MapReduce and Flume/Jupiter). Typical use cases include streaming analytics, ETL, and data pipeline tasks such as enriching or grouping events in real time.
Google Cloud Dataflow serves as the central processing engine for data pipelines on GCP. For example, you might use Cloud Dataflow to ingest events from Google Pub/Sub, transform them, and load into BigQuery (for streaming ETL), or to read a large file from Cloud Storage, process and aggregate it, and write the results to a database (batch ETL). Dataflow is popular because it provides one unified model for batch and streaming, meaning you don’t have to maintain separate systems for each.
It fits best for data engineering teams who prefer to define their pipelines in code (Beam’s model encourages a functional style of defining transformations) and want the benefits of not worrying about servers.
Key Strengths
- Unified Batch + Stream Processing: Dataflow (via Beam) uses a unified programming model for both batch and streaming, allowing code reuse and easier transition from batch jobs to near-real-time pipelines. This is a big plus for organizations evolving from nightly jobs to streaming.
- Auto-Scaling & Optimization: Being serverless, Dataflow automatically scales workers up or down based on data volume and pipeline complexity. It also does dynamic work rebalancing (moving work from slow workers) which optimizes throughput and latency without manual tuning.
- Exactly-Once and Windowing: Dataflow/Beam excels in event-time processing and windowing (handling out-of-order data gracefully). It provides exactly-once processing guarantees, crucial for correctness in streaming pipelines (e.g., no double counting on retries).
- Managed Service with SLA: As a GCP service, Dataflow has high availability, reliability, and is fully managed – no clusters to manage, patches to apply, or downtimes for upgrades. You get Google’s expertise (Dataflow was behind Google’s own services) for your pipelines.
- Integration with Google Ecosystem: It has built-in connectors and optimizations for GCP services like Pub/Sub, BigQuery, Cloud Storage, Bigtable, Spanner, etc., making pipelines involving those systems very efficient and easier to set up. For instance, Dataflow can stream directly into BigQuery with low latency.
Ideal Use Case
Google Cloud Dataflow is ideal for teams using Google Cloud Platform who need large-scale data processing, particularly if they need real-time data pipelines. If you’re a tech company processing user analytics events by the billions, Dataflow is a great choice to do per-user sessionization or anomaly detection on the fly.
Or if you’re a utility company capturing IoT sensor data, Dataflow can ingest and analyze those streams continuously. It’s also very suitable for building data lakes and warehouses on GCP: a common pattern is to use Dataflow to ETL data from various sources into BigQuery or Cloud Storage in a structured format.
Because you can use SQL (via Beam SQL) or code, it’s flexible for different skill sets. Dataflow is often chosen by organizations that value “future-proofing” their pipelines – even if they only do batch now, they foresee streaming needs and want a tool that covers both. It’s best for scenarios where you require scalable, fault-tolerant processing without ops overhead.
Dataflow is also ideal if you want to avoid vendor lock on just Google, the Beam model means your code could, in theory, run on other Beam runners (like Spark or Flink) if you ever left GCP. For smaller workloads, Dataflow works, but its true strength shines at large scale or where complex time-based aggregations are needed (Beam’s model handles lateness, windows, triggers elegantly). In summary, choose Dataflow when you’re committed to GCP and need an enterprise-grade pipeline engine that handles both streaming and batch, with minimal management.
Limitations
One limitation of Dataflow is that it requires using the Apache Beam model, which can have a learning curve. Developers not used to a distributed dataflow paradigm or functional style might find it initially complex to write Beam pipelines.
While Google has added Dataflow templates and even Dataflow SQL for simpler cases, for complex logic you’ll need to write code, meaning Dataflow is less friendly to non-programmers compared to some GUI-based ETL tools.
Debugging Dataflow jobs can sometimes be tricky: you rely on Cloud Monitoring logs and the Dataflow UI, but if something goes wrong deep in a pipeline, root cause analysis may take effort (though the tools have improved).
Another consideration is latency: while Dataflow is near-real-time, ultra-low-latency systems (sub-second) might need other approaches (e.g., directly using Pub/Sub and custom consumers) – Dataflow adds a bit of overhead for its scaling and exactly-once features.
Pricing Model
Google Cloud Dataflow pricing is based on the actual resources consumed by your jobs. Specifically, you pay for vCPU hours, memory, and persistent storage used during pipeline execution.
Dataflow has two modes: streaming and batch, but pricing is similar conceptually. For example, if your Dataflow job uses an average of 4 vCPUs and 16 GB of memory for 1 hour, you pay for 4 vCPU-hours and 16 GB-hour of memory, at the GCP rates (which might be, say, $0.056 per vCPU-hour and $0.003 per GB-hour, region-dependent).
Additionally, Dataflow charges for data processed if using Shuffle or Streaming Engine (which are internal features to optimize data exchange). There is also a small cost for Dataflow Shuffle storage (per GB-month) if you use batch jobs with large shuffles that spill to disk.
Google provides a handy breakdown: typically, streaming jobs might cost more per hour because they’re always on, whereas batch jobs cost just while running. The nice thing is Dataflow auto-scales, so if your job is idle or smaller, it reduces resources, saving cost.
Here’s Google Cloud’s pricing calculator for a rough cost estimate.
There’s also a free usage tier: currently, Dataflow offers some free processing each month (e.g., first 50 hours of certain machine types). Pricing transparency is decent, you can see in the Dataflow console exactly how many vCPU/mem hours were used. And since it uses sustained use discounts on GCP, longer jobs might get automatic discounts. Summing up: no license fees, pure resource usage charges, which aligns with the serverless value proposition.
Integrations and Ecosystem
Cloud Dataflow, via Apache Beam, has connectors for many data systems. On GCP, it natively integrates with Pub/Sub (message ingestion), Cloud Storage (source/sink for files), BigQuery (can read and write, including a convenient BigQueryIO), Cloud Bigtable, Spanner, Firebase, etc. Dataflow can also connect to external databases or systems using Beam’s IO connectors: for example, there are connectors for Kafka, JDBC (any database), MongoDB, Elasticsearch, Amazon Kinesis, etc.
This makes Dataflow suitable not just for all-GCP pipelines but also for bridging outside data into GCP. In practice, common integrations are reading from Kafka and writing to BigQuery, or reading from on-prem databases via Cloud VPN into Dataflow and outputting to cloud storage.
The Beam SDK also allows writing custom connectors if one doesn’t exist, and the community has contributed many. Another integration point is with other GCP services: Dataflow can be orchestrated using Cloud Composer (Airflow) or Cloud Functions/Cloud Run triggers. For instance, you might trigger a Dataflow batch job via a Cloud Function when a file lands in a bucket.
Dataflow templates allow you to create reusable pipeline configurations that non-engineers can execute from the GCP Console or via an API call (e.g., a marketing team could run a specific Dataflow template to load new data).
Google also provides Dataflow SQL within BigQuery UI or Dataflow notebooks, which can turn an SQL query into a Dataflow job under the hood, further integrating with BigQuery for ease of use.
Customer reviews and considerations
Google Cloud Dataflow holds an average rating of 4.2/5 on G2, based on 47 user reviews. Users often commend its fully managed, serverless model and seamless integration within the Google Cloud ecosystem, allowing them to build streaming and batch pipelines without managing underlying infrastructure.
For prospective users, key considerations include:
- Cost management can be tricky, particularly for high-volume or continuously running pipelines, where unanticipated resource use can inflate bills.
- Some users point to limitations in debugging, visibility, and error handling (e.g. sparse logs, difficulty cancelling runs) which can slow development iterations.
- Also, users mention that advanced use cases, especially around watermarking, custom connectors, or cross-cloud integration, can require deeper expertise or custom development.
Verdict
Best for Google Cloud users who need a powerful, unified engine for both streaming and batch pipelines with minimal ops overhead. Google Cloud Dataflow stands out when real-time analytics and scalable ETL are priorities, offering an advanced solution to process data “at Google scale” without managing servers.
7. Apache Spark by Apache Software Foundation
Apache Spark is an open-source distributed computing engine for big data processing and analytics. Renowned for its speed and ease of use compared to earlier frameworks like Hadoop MapReduce, Spark provides a unified platform for batch processing, stream processing, machine learning, and graph analytics.
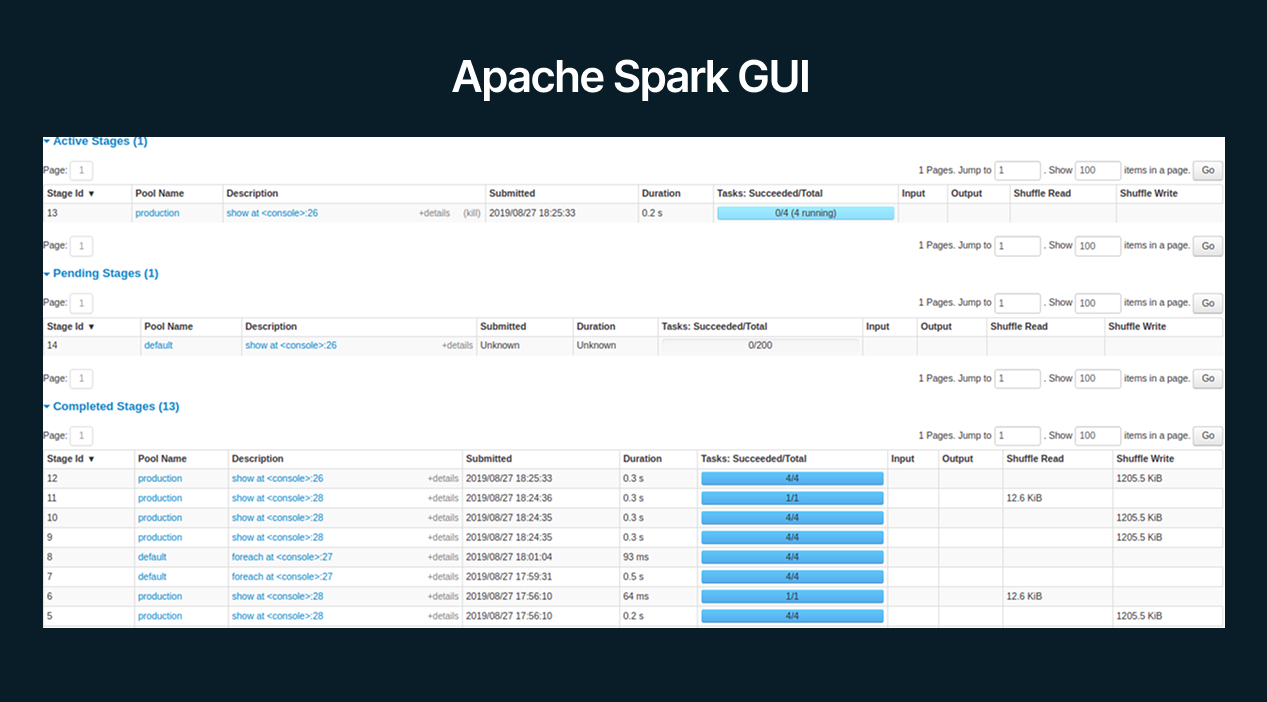 At its core, Spark allows users to write parallel programs using simple abstractions like Resilient Distributed Datasets (RDDs) or higher-level APIs (DataFrames, Datasets) and have the runtime handle distributing that work across a cluster of machines.
At its core, Spark allows users to write parallel programs using simple abstractions like Resilient Distributed Datasets (RDDs) or higher-level APIs (DataFrames, Datasets) and have the runtime handle distributing that work across a cluster of machines.
Spark keeps data in memory between steps (when feasible), which can lead to order-of-magnitude faster performance for iterative algorithms and data analysis. It supports multiple languages – originally Scala and Java, but also PySpark for Python and Spark SQL with SQL queries, plus R. Because of its versatility, Spark has become a default choice for implementing data pipelines in many organizations, either self-managed or via cloud services like Databricks, Amazon EMR, or Google’s Dataproc.
Key Strengths and Specializations:
- High Performance for Big Data: Spark’s in-memory computation and optimized execution engine is faster than most solutions. It efficiently handles batch jobs on TB-scale data and iterative computations for ML.
- Unified Engine (Batch, Streaming, ML): Spark offers a rich stack of libraries: Spark SQL for structured data, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing. This means you can use one framework for varied pipeline steps (e.g., ETL then ML model training) all in one program.
- Developer-Friendly APIs: With support for Python (PySpark), Scala, Java, and R, Spark makes distributed programming accessible to many developers. The high-level DataFrame API and SQL interface allow data engineers and analysts to be productive quickly, using DataFrame operations or SQL queries to transform data.
- Ecosystem & Community: Spark has one of the largest open-source big data communities, with over 1,000 contributors and widespread adoption. There are countless resources, books, and a vast ecosystem of connectors (e.g., for Kafka, Cassandra, ElasticSearch).
- Scalability & Fault Tolerance: Spark runs on clusters from a few nodes to thousands. It automatically handles partitioning the data and computations. If a task fails, Spark’s RDD lineage and DAG execution allow it to recompute lost partitions (fault tolerant). This makes Spark pipelines robust for long-running jobs on large clusters.
Ideal Use Case
Apache Spark is ideal for data engineering and data science teams that need to process large datasets or complex transformations in a distributed manner.
If you’re dealing with data volumes that exceed what a single machine can handle (hundreds of GB to many TB), Spark is often the go-to solution. Common use cases include: batch ETL jobs aggregating logs, joining big datasets like customer records with event data, computing statistics or features for machine learning at scale, and transforming unstructured data (text, images at scale) into structured form.
Thanks to Structured Streaming, Spark can also be used for pipelines that need near-real-time results (like updating dashboards or triggering alerts from streaming data). However, Spark streaming is micro-batch oriented, so if ultra-low latency (sub-second) is required, other specialized tools might be better.
Spark is often deployed by mid-size to large enterprises and tech companies, but with cloud services, even startups use Spark on managed platforms to future-proof their data pipelines. Essentially, if your data processing needs have outgrown a single server or require sophisticated parallel algorithms, Spark is an excellent choice.
Limitations
While powerful, Apache Spark has a few considerations.
The memory management, although much improved, can be tricky, an inefficient transformation might cause excessive data spill to disk. Spark applications also traditionally have somewhat high overhead to start (the job startup can take a bit of time, though this is mitigated in long-running sessions or clusters).
For small data or simple tasks, using Spark might be overkill compared to Python pandas or a database. In streaming use cases, Spark’s micro-batch processing introduces a bit more latency than true event-by-event systems; there’s always a trade-off between throughput and latency.
Another con: Spark requires cluster resources – managing a Spark cluster (on Hadoop YARN or Kubernetes) can be complex if not using a managed service. Tuning a Spark job for optimal performance can be an art, dealing with executor memory, core counts, serialization, etc.
Another limitation: Spark’s default is eventually consistent by design for streaming and doesn’t natively provide exactly-once semantics for all sinks unless carefully handled (though with checkpointing and idempotent sinks, you can achieve it).
Pricing Model
Apache Spark itself is free and open-source. If you run it on your own hardware or VMs, you’re not paying for Spark licenses, only the infrastructure and manpower to maintain it.
Pricing comes into play with how you choose to deploy Spark: many will use managed Spark services for convenience.
- Databricks offers Spark as a service with a web interface, and they charge typically on a per-node, per-hour basis (Databricks uses “DBUs” which are a unit of processing time, plus the underlying cloud VM costs).
- Amazon EMR offers Spark on its managed Hadoop service, charging a small premium on top of EC2 instance costs (and you pay for the EC2s by the second).
- Google’s Dataproc and Azure’s HDInsight similarly charge for instances plus a service fee (Dataproc’s fee is very minimal; it’s mostly the compute cost). So the pricing model depends: if self-managed, cost is cluster nodes (which can be made ephemeral per job to save money).
On Azure Databricks, you’d have a cost per cluster per hour; for example, an 8-node cluster might be, say, $0.20/DBU * number of DBUs plus the VM cost.
Typically, expect something like a few dollars per hour for a decent sized cluster, scaling with size. Also consider if you use Spark on Kubernetes, you just pay for the K8s infrastructure.
In essence, the cost of Spark scales with the compute and memory resources you allocate. There’s no direct Spark subscription fee unless you pay for vendor support or enterprise platforms. However, enterprise adoption often involves paying for support (e.g., Cloudera or Databricks).
Integrations and Ecosystem
Apache Spark has a massive ecosystem of data sources.
Spark is frequently used with Kafka for building streaming pipelines, with Spark consuming from Kafka topics and writing results out to sinks like HDFS or databases.
In the cloud, managed Spark (Databricks, EMR, etc.) come with connectors tailored to cloud storages and services.On Databricks, you have optimized connectors for Azure Data Lake or AWS S3, as well as for Delta Lake (Databricks’ open-source storage layer that adds ACID to Spark).
Speaking of Delta Lake, it’s an important part of Spark’s ecosystem – an open-source format that many use to make Spark data lakes behave more like databases (with ACID transactions and time travel).
Spark integrates with Hive Metastore for table metadata, so Spark jobs can treat data in a data lake as SQL tables for easier management. The MLlib library integrates with various data formats and can save models that integrate with other tools.
Spark’s API also allows calling out to external libraries, so integration with Python’s ecosystem is possible (though large data should use Spark APIs, sometimes you can use Pandas within a single machine subset if needed).
Many BI tools can connect to Spark SQL via JDBC/ODBC drivers (Databricks provides ODBC/JDBC endpoints for clusters, and open-source Spark has ThriftServer for JDBC). This means analysts can query Spark data from tools like Tableau or PowerBI, turning Spark into a quasi-database engine.
The community constantly extends Spark: for instance, GraphX for graph processing might integrate with graph databases or GraphFrames on top of Spark SQL.
Customer reviews and considerations
Apache Spark holds an average rating of 4.3/5 on G2, based on 54 user reviews. Users frequently commend its speed, scalability, and broad support for both batch and streaming workloads, as well as its rich ecosystem of libraries (e.g. MLlib, GraphX).
For prospective adopters, key considerations include:
- Spark’s operational and tuning complexity is often cited: poor configuration or resource misallocation (memory, shuffles, skew) can lead to degraded performance or costly failures.
- It may be overkill for smaller datasets or simpler transformation needs, given its overhead and resource demands.
- Debugging and error diagnosis in distributed jobs is often reported as nontrivial.
Verdict
Best for large-scale data transformation and analytics where speed and a unified engine for batch, streaming, and ML are needed. Apache Spark is the workhorse for companies that need to crunch big data fast, offering a potent mix of performance, flexibility, and a thriving ecosystem.
Build a Reliable Data Pipeline with Vodworks’ Data Readiness Package
Now that you’ve seen how the leading pipeline tools fit together, the next step is turning that knowledge into actions, without disrupting day-to-day operations.
That’s precisely what the Vodworks Data & AI Readiness Package delivers. We start with a Use-Case & Stack Exploration sprint that pressure-tests candidate initiatives against business value, data availability, and expected payback—while shortlisting the right tools (e.g., Airflow, Kafka, NiFi, Glue/ADF/Dataflow, Spark) for your context.
By the end of the workshop, you’ll have preliminary insights and a prioritized list of pipeline use cases sized for ROI, plus an initial view of the target data stack.
Next, our architects go deep on data quality, infrastructure robustness, and organizational readiness. You’ll receive a data readiness report, an end-to-end pipeline/infrastructure map, and an organizational assessment, clarifying where friction hides and what it costs to remove.
Prefer hands-on delivery? The same specialists can clean data, modernize pipelines, and operationalize models, so your first production use case ships on time, within guardrails, and with ROI visible on the dashboard.
Book a 30-minute discovery call with a Vodworks solution architect to review your data estate, choose the right tools, and blueprint a pipeline architecture that compounds value.

About the Author
Abdul Qayyum
With more than 17 years in software development, Abdul is a Software Architect has extensive expertise in Java, Big Data, AI/ML, and Blockchain technologies. His main role is to deliver strong architecture for back-end and middleware solutions to our clients across diverse business domains, including Telco, E-commerce, Blockchain, Media Streaming, Social Apps, and IoT.


Accelerate Your Projects With Our On-Demand Developers
Let's TalkTalent Shortage Holding You Back? Scale Fast With Us
Frequently Asked Questions
How do you handle different time zones?

With a team of 150+ expert developers situated across 5 Global Development Centers and 10+ countries, we seamlessly navigate diverse timezones. This gives us the flexibility to support clients efficiently, aligning with their unique schedules and preferred work styles. No matter the timezone, we ensure that our services meet the specific needs and expectations of the project, fostering a collaborative and responsive partnership.
What levels of support do you offer?
We provide comprehensive technical assistance for applications, providing Level 2 and Level 3 support. Within our services, we continuously oversee your applications 24/7, establishing alerts and triggers at vulnerable points to promptly resolve emerging issues. Our team of experts assumes responsibility for alarm management, overseas fundamental technical tasks such as server management, and takes an active role in application development to address security fixes within specified SLAs to ensure support for your operations. In addition, we provide flexible warranty periods on the completion of your project, ensuring ongoing support and satisfaction with our delivered solutions.
Who owns the IP of my application code/will I own the source code?
As our client, you retain full ownership of the source code, ensuring that you have the autonomy and control over your intellectual property throughout and beyond the development process.
How do you manage and accommodate change requests in software development?
We seamlessly handle and accommodate change requests in our software development process through our adoption of the Agile methodology. We use flexible approaches that best align with each unique project and the client's working style. With a commitment to adaptability, our dedicated team is structured to be highly flexible, ensuring that change requests are efficiently managed, integrated, and implemented without compromising the quality of deliverables.
What is the estimated timeline for creating a Minimum Viable Product (MVP)?
The timeline for creating a Minimum Viable Product (MVP) can vary significantly depending on the complexity of the product and the specific requirements of the project. In total, the timeline for creating an MVP can range from around 3 to 9 months, including such stages as Planning, Market Research, Design, Development, Testing, Feedback and Launch.
Do you provide Proof of Concepts (PoCs) during software development?
Yes, we offer Proof of Concepts (PoCs) as part of our software development services. With a proven track record of assisting over 70 companies, our team has successfully built PoCs that have secured initial funding of $10Mn+. Our team helps business owners and units validate their idea, rapidly building a solution you can show in hand. From visual to functional prototypes, we help explore new opportunities with confidence.
Are we able to vet the developers before we take them on-board?
When augmenting your team with our developers, you have the ability to meticulously vet candidates before onboarding. We ask clients to provide us with a required developer’s profile with needed skills and tech knowledge to guarantee our staff possess the expertise needed to contribute effectively to your software development projects. You have the flexibility to conduct interviews, and assess both developers’ soft skills and hard skills, ensuring a seamless alignment with your project requirements.
Is on-demand developer availability among your offerings in software development?
We provide you with on-demand engineers whether you need additional resources for ongoing projects or specific expertise, without the overhead or complication of traditional hiring processes within our staff augmentation service.
Do you collaborate with startups for software development projects?
Yes, our expert team collaborates closely with startups, helping them navigate the technical landscape, build scalable and market-ready software, and bring their vision to life.
Our startup software development services & solutions:
- MVP & Rapid POC's
- Investment & Incubation
- Mobile & Web App Development
- Team Augmentation
- Project Rescue
Subscribe to our blog
Related Posts
Get in Touch with us
Thank You!
Thank you for contacting us, we will get back to you as soon as possible.
Our Next Steps
- Our team reaches out to you within one business day
- We begin with an initial conversation to understand your needs
- Our analysts and developers evaluate the scope and propose a path forward
- We initiate the project, working towards successful software delivery