

6 Data Quality Trends for 2026 Shaping Reliable AI and BI

November 4, 2025 - 10 min read

Author

Billions are flowing into AI, yet the winners are those who start at the root: data quality. By treating data as a product and building trust at the source of data ingestion, leaders ensure the top-tier quality of data that fuels AI engines.
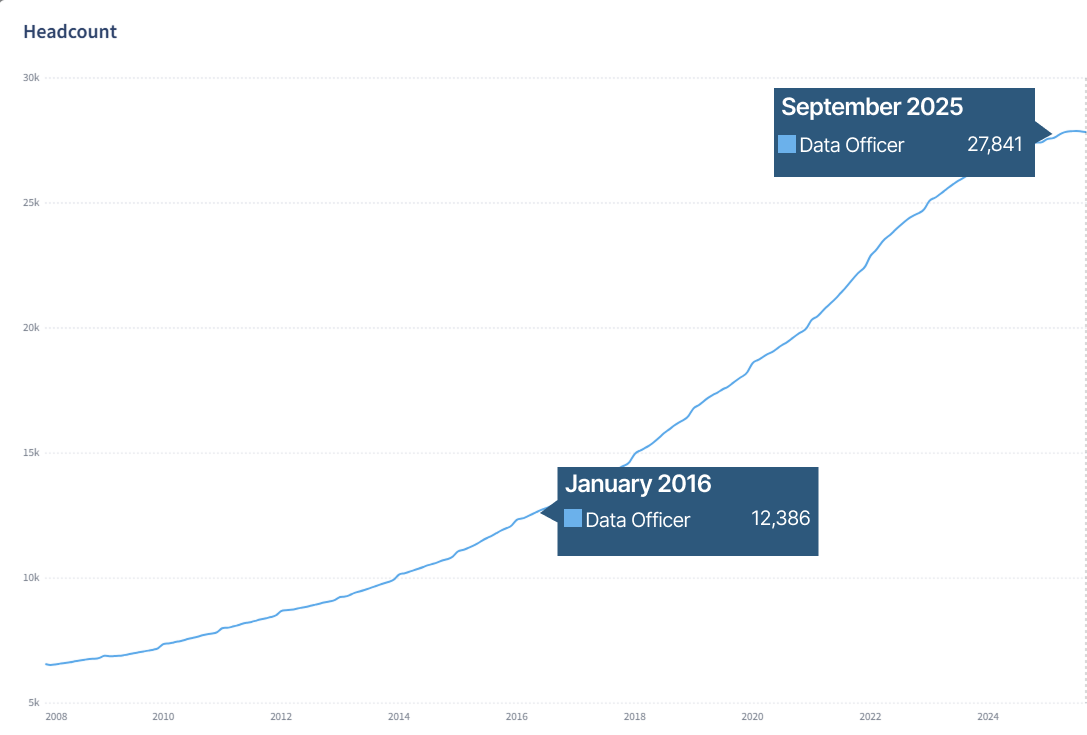
Managing company data and maintaining its quality is not easy. Chief Data Officers who were rare before are now among the most sought-after technical leaders. Since 2016, the number of Data Officers has grown 125% (from 12,386 to 27,841, according to Revelio Labs).
 Companies worldwide recognise the urgency of collecting and managing data effectively. In this article, we map the key data quality trends shaping 2026 and what to do about them. We cover topics from embedding data ownership in core business processes to synthetic data generation and how it can close the rising gap in training data. For data professionals, keeping up with these trends will be crucial to staying relevant in 2026.
Companies worldwide recognise the urgency of collecting and managing data effectively. In this article, we map the key data quality trends shaping 2026 and what to do about them. We cover topics from embedding data ownership in core business processes to synthetic data generation and how it can close the rising gap in training data. For data professionals, keeping up with these trends will be crucial to staying relevant in 2026.
Quality at the Source: Business Leaders Need to Step Up
When business leaders own data quality, teams can cut downstream rework, accelerate decisions, and strengthen compliance across your enterprise.
Data is a strategic asset. Its value is understood best by the people who use it to make daily choices on pricing, risk, supply chain, customer experience, and other operations.
When business units take ownership of data quality, they align standards with operational goals, customer outcomes, and performance metrics. This shift turns data quality from a technical clean-up activity into a driver of growth, cost control, and resilience.
Data silos and inconsistencies still occur as top obstacles, even despite decades of innovations in data cleaning and preparation tech. This shows that the problem often lies beyond IT.
Data cleansing treats symptoms rather than root causes. Leading firms now embed validation, lineage checks, and governance controls directly into critical processes such as KYC, onboarding, supply chain, and finance.
The result is accurate, complete, and timely data throughout the lifecycle, with faster analytics and fewer data anomalies requiring fixes. Deloitte notes that while quality initiatives carry cost, the benefits in decision speed and operational savings far outweigh them.
Poor quality data is not a minor annoyance. Experian reports that 75% of organisations that improved data quality exceeded their annual objectives in some way.
McKinsey finds that data-driven leaders can attribute up to 20 percent of EBIT to AI-powered capabilities. The outcome of this investment directly depends on the quality and amount of data that AI has access to.
Business-led data stewardship creates greater accountability because the teams responsible for outcomes also own the data that drives them. It reduces downstream fixes, improves decision quality, and enhances auditability and compliance. Firms that adopt this discipline move faster, make better decisions, and build a durable digital advantage.
The Rise of Data Observability
When you observe data health in real time across pipelines, models, and dashboards, you cut data downtime, speed decisions, and protect regulatory posture.
Data observability gives teams a continuous view of the health and reliability of your data across its lifecycle. It detects issues early and shortens time to resolution, which directly reduces data downtime and restores trust in analytics and AI outputs.
High-performing data organisations anchor observability on five practical pillars. These pillars let you spot anomalies early, trace impact, and automate response.
- Freshness: track whether data arrives on time so reports and models use current facts rather than stale snapshots.
- Volume: Monitor row counts and completeness to catch silent drops, spikes, or partial loads that corrupt insight.
- Distribution: Watch statistical properties such as ranges and null rates to detect drift that can mislead decisions and AI predictions.
- Schema: Alert on breaking changes to tables, fields, and contracts before downstream pipelines fail.
- Lineage: Map end to end data flows so you can assess blast radius, prioritise fixes, and notify owners fast.
 Source: https://grafana.com/blog/2025/03/25/observability-survey-takeaways/
Source: https://grafana.com/blog/2025/03/25/observability-survey-takeaways/
Organisations use data observability to prevent bad data from reaching executives and customers. The approach reduces incident volume, lowers rework, and accelerates analytics delivery on modern cloud stacks. Google Cloud highlights the role of observability in cutting data downtime and improving collaboration across data teams.
The market’s rapid growth signals mainstream adoption. Analysts project the data observability segment to reach about 4.7 billion USD by 2030 at a 12.2 percent CAGR.
As data stacks keep growing, data observability is no longer a niche engineering concern. Adoption of traces has crossed 50%, and C-suite sponsorship is now common, which accelerates investment in shared platforms and SLOs.
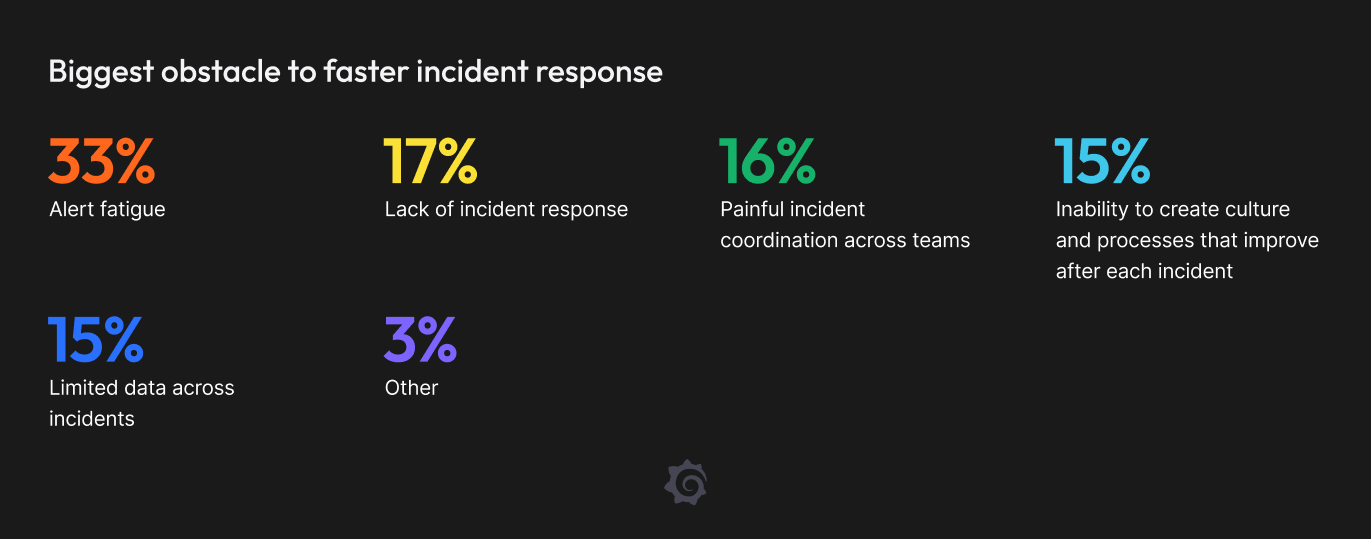 In 2026, the focus will be on reducing alert fatigue, improving incident coordination, and reducing response times. Source.
In 2026, the focus will be on reducing alert fatigue, improving incident coordination, and reducing response times. Source.
As of now, complexity and alert fatigue are the top blockers to faster incident response. Teams that prioritise data observability counter this with SLO-driven operations to align alerts with user impact, AI-assisted noise reduction and root-cause hints, and full-stack observability that connects infrastructure signals to data pipelines, models, and dashboards.
In 2026, companies will streamline toolsets, enhance interoperability, and prioritise governance around Mean Time to Resolution (MTTR) and accountability instead of data volume.
AI Takes the Lead in Metadata Management
Before the widespread integration of AI, metadata management systems primarily focused on structured, manual, or rule-based methods. That’s why metadata management was an extremely labour-intensive process requiring high levels of human intervention.
In recent years, with growing pipelines and AI’s insatiable appetite for data, the work of extracting tags, tracking lineage, and enforcing policy can no longer rely on spreadsheets and human memory. Luckily, AI helps close that gap by reading schemas, inspecting content, and proposing structure at the speed your datasets change.
The first visible change is at the ingestion stage. Models now scan tables, files, and streams to suggest classifications, detect sensitive fields, and map relationships.
For example, OpenMetadata uses NLP to identify and tag sensitive personally identifiable information (PII). For example, in the screenshot below, you can see the customer’s name and the most recent order are automatically marked as PII-sensitive columns.
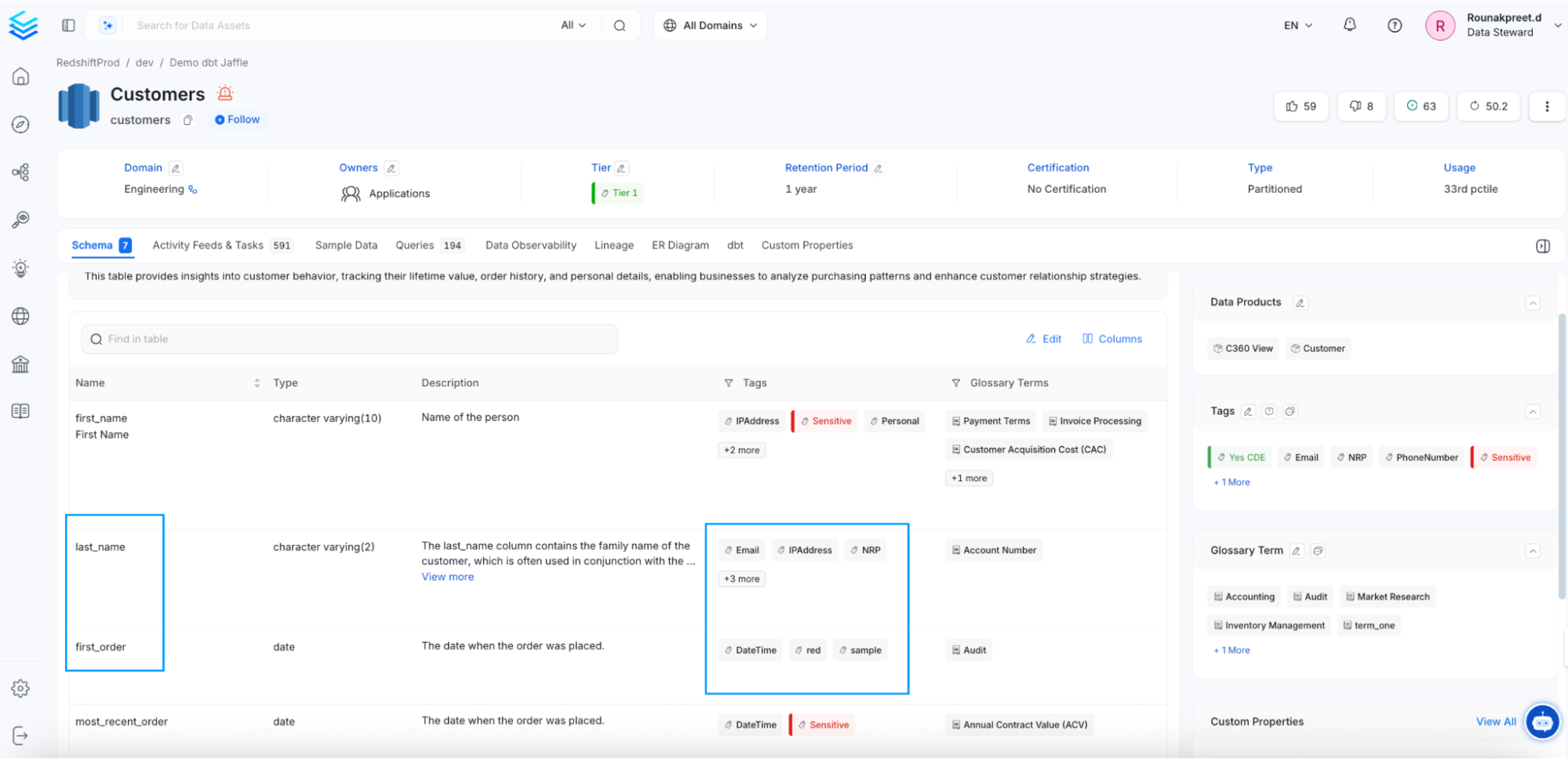 OpenMetadata shows autotagged columns containing PII data.
OpenMetadata shows autotagged columns containing PII data.
Informatica’s CLAIR AI engine goes even further, allowing users to track lineage, explore data, and create entire data pipelines using natural language.
Despite the undeniable usefulness of AI in metadata management, the technology is far from flawless. AI’s data dependency is a significant limitation for situations where data is scarce, biased, or unrepresentative. Besides, Modern AI models operate as black boxes, making it difficult to interpret and validate their decision-making process.
Lack of transparency and access to diverse datasets compromises the performance of models and limits trust in the output of AI systems.
Next steps for AI in metadata management will be the introduction of multimodal models that can process different data types (video, text, audio, images) within a single system. This will help metadata descriptions reflect the full context of heterogeneous content.
At the same time, GenAI metadata enrichment will enable teams with more accurate information retrieval and contribute to effective decision-making. GenAI systems can produce summaries, descriptive tags, and contextual insights from raw data that can be adapted to specific users and domains.
Data Quality Goes Full-Stack
Data quality can no longer live only with governance. Organisations need shared responsibility across data engineering, data science, and analytics so trust is designed into pipelines, models, and dashboards. Gartner highlights that integrating data quality into corporate culture is one of the crucial steps to raise quality and avoid rising costs.
The primary reason is the cost of poor data quality. Benchmarks place average organisational losses at 12.9 million per year, while IBM estimates a 3.1 trillion annual impact on the US economy alone.
That’s why data quality should be integrated into every data function to minimise expenses, reduce risk, and convert analytics into EBIT growth.
As a starting point, name business aligned data owners and embed stewards inside product and analytics units. This creates end to end accountability from data capture to board reporting.
Move from retrospective cleansing to controls within daily workflows. Integrate validation, lineage, schema checks, and feedback loops into ETL, orchestration, and reporting so issues are fixed at source.
Reuse existing platforms for rules, observability, and drift monitoring. Treat MLOps as a continuous discipline that tests, deploys, and monitors data and models together to keep outputs reliable.
Bridging the Data Gap with Synthetic Data
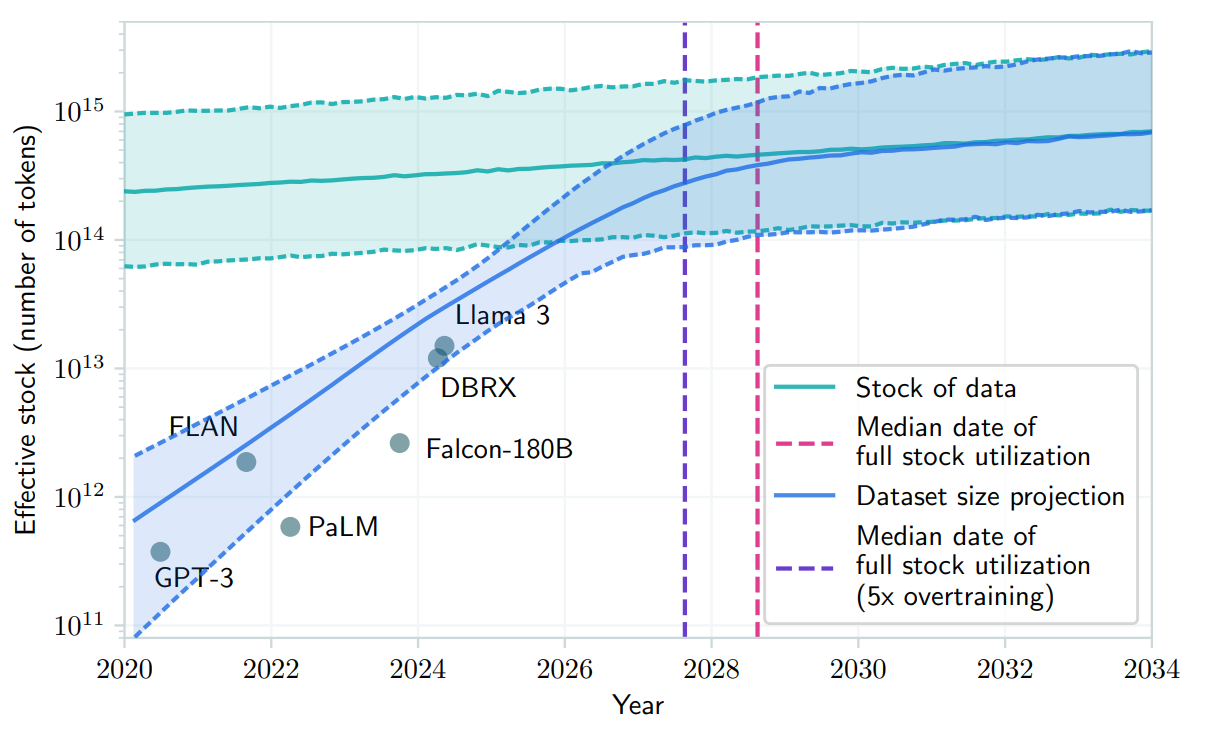
According to a recent study, 2028 will be the year when AI models will run out of human-generated data for training.
 Even with the current rate of training and model development, AI models still have limited knowledge, especially where circumstances require extensive domain knowledge.
Even with the current rate of training and model development, AI models still have limited knowledge, especially where circumstances require extensive domain knowledge.
In many AI projects, the problem is not the integration of AI models, but their enablement with the right data. In regulated domains, such as healthcare or finance, data is scarce because it’s protected with privacy laws such as GDPR, CCPA, and the EU AI Act.
Synthetic data becomes a core tool for training models where globally available data is not enough. Gartner predicts that by 2030, synthetic data will replace real data in AI models.
With the emergence of AI, companies have the potential to produce synthetic data at a massive scale. For example, OpenAI’s DevDay keynote states that their API platform produces 6B tokens per minute. At this rate, it takes around 6 days to generate the same 36.5T words, roughly the same number as Common Crawl has, a repository of global web crawl data.
Beyond regulatory compliance, synthetic data has practical advantages. It’s a cost-effective and fast method of generating data that would otherwise take months or years to collect organically.
However, opinions on training AI systems with synthetic data are mixed. One of the challenges is that training on synthetic data might lead to homogenous and unrealistic outputs.
Researchers believe that training on synthetic data shows much promise in domains of knowledge where outputs are easy to verify, such as mathematics, programming, and gaming.
For example, here’s an image from the experiment where a model was continuously retrained on synthetic data. Each time the model was retrained, its output deviated from the original data. By the 50th iteration, the underlying data changed completely, and by 2000 rounds of retraining, each group collapsed into a tiny dot with no spread at all.
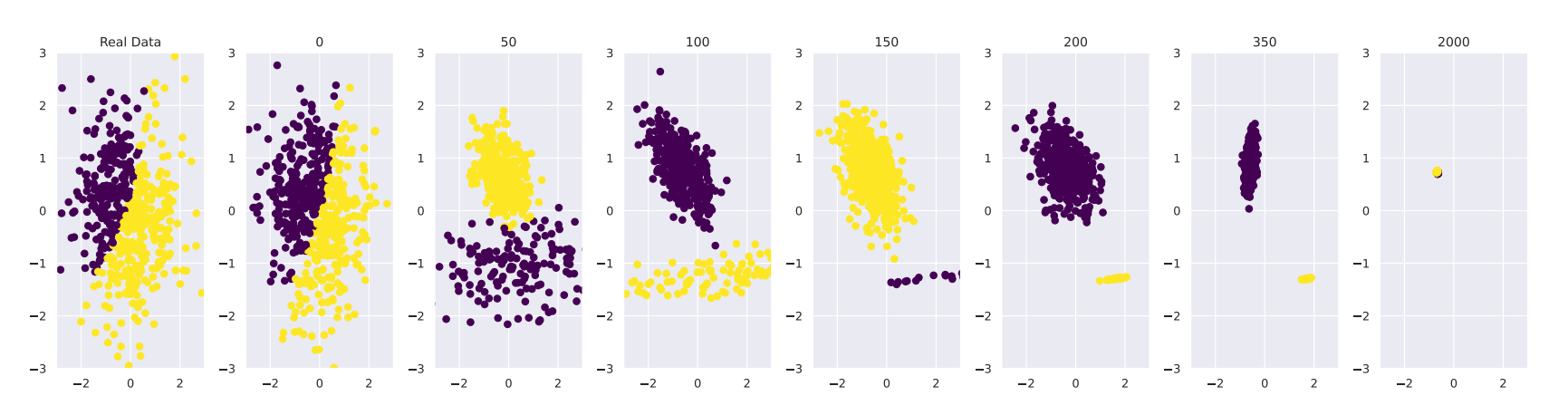 The Curse of Recursion: Training on Generated Data Makes Models Forget, 2023, Ilya Shumailov, et al.
The Curse of Recursion: Training on Generated Data Makes Models Forget, 2023, Ilya Shumailov, et al.
That scale of synthetic data generation matters only if the data is trustworthy.
That’s why the next crucial step after generation is validation, which asks whether the new data mirrors real-world structure, works for the intended task, and protects people’s privacy.
In practice, this starts with fidelity checks: compare distributions, correlations, and multivariate patterns to the source to confirm the synthetic set preserves the shape of reality. Modern guides recommend a mix of univariate overlap tests and relationship checks so you catch both obvious drift and subtle dependency breaks.
Once the data “looks right,” teams test the utility by running the synthetic set through the job it is meant to do. A common approach is to train on synthetic and evaluate on held-out real data, then compare that score to a model trained and tested on real data. If performance holds, the dataset is useful; if not, you iterate on the generator or tighten constraints.
Finally, you verify privacy. The goal is to keep re-identification risk low while retaining enough signal for the task. Practitioners measure singling-out or linkage risks and look for leakage in rare outliers, since those can expose individuals.
When working with synthetic data, it's very challenging to achieve high performance across all three dimensions simultaneously, as improvements in one area often compromise another. A practical approach is to first generate a highly realistic synthetic dataset and then apply privacy safeguards, rather than attempting to restore realism and utility after the data has been excessively distorted for privacy.
 Centralisation as the backbone of data democratisation
Centralisation as the backbone of data democratisation
In the last decade, the “data-driven culture” trend has gained strong momentum. Organisations were encouraging every business unit to be guided by data and metrics in day-to-day processes instead of flying blindly.
Data-driven transition had two main blockers:
- Business units, especially non-technical ones, didn’t have the right tools to record data.
- Organisations struggled to provide each department with tools for data analytics. Dashboards took too long to build, the technical threshold was too high for regular users to build them independently, and there was no unified way to answer all ad-hoc analytics questions each department could have.
Cloud migration and SaaS tools solved the first problem. Now, most tools have data connectors that can extract data and store it in their preferred storage.
In the last few years, AI has become a solution to the second problem.
Augmented analytics expands the ability of employees to interact with data at a contextual level.
For example, Google Sheets now has integration with Gemini that allows users to interact with their data through natural language. Non-technical users can visualise data, clean data, and create complex formulas using only natural language. If previously, an entire department could have only one “Excel whiz” that knew how to do complex operations in spreadsheets, now each employee becomes that whiz.
 Besides, department-specific tools, like CRMs, marketing platforms, or accounting software, also start implementing augmented analytics capabilities.
Besides, department-specific tools, like CRMs, marketing platforms, or accounting software, also start implementing augmented analytics capabilities.
The opportunity is real, but so are the risks. Many augmented analytics features still behave like a black box. They produce answers without clear reasoning, provenance, or links back to the underlying data. Under deadline pressure, non-technical users may accept results they cannot verify.
A widespread example of this is AI ad optimisation. Marketers often struggle with intrusive AI ad suggestions, which usually do more harm than good.
 The same caution applies to embedded analytics inside business apps. If users cannot check data quality or see how the system produced an answer, they should not trust it.
The same caution applies to embedded analytics inside business apps. If users cannot check data quality or see how the system produced an answer, they should not trust it.
This is why having a single source of truth matters more than ever. Moving analysis-grade data into the company warehouse (or another governed storage) makes quality checks possible (mapping, naming conventions, and freshness), and allows teams to join data across sources. That combination improves trust and uncovers insights that wouldn’t be visible in siloed tools.
Vodworks AI Readiness Package: Your Fast Lane to Trusted Data Foundations
Turn the trends in this article into a working data quality program. Vodworks can help you design quality at the source, make data health traceable, and centralise data from disparate sources in a storage of your choice.
We start by assessing your current state of data quality, structure, storage, governance, and compliance, then map a targeted path to a single source of truth and observable, reliable pipelines.
From there, we design the data strategy and architecture, implement ingestion, transformation, and enrichment with built-in validation and monitoring, and reinforce it with access controls, audit trails, and policy-as-code governance.
Our engineers operationalise the stack so quality holds up in production and reporting, with MLOps applied to maintain reliable models and analytics.
Book a 30-minute discovery call with a Vodworks solution architect to review your data estate and discuss your data use cases.

About the Author
Abdul Qayyum
With more than 17 years in software development, Abdul is a Software Architect has extensive expertise in Java, Big Data, AI/ML, and Blockchain technologies. His main role is to deliver strong architecture for back-end and middleware solutions to our clients across diverse business domains, including Telco, E-commerce, Blockchain, Media Streaming, Social Apps, and IoT.


Accelerate Your Projects With Our On-Demand Developers
Let's TalkTalent Shortage Holding You Back? Scale Fast With Us
Frequently Asked Questions
How do you handle different time zones?

With a team of 150+ expert developers situated across 5 Global Development Centers and 10+ countries, we seamlessly navigate diverse timezones. This gives us the flexibility to support clients efficiently, aligning with their unique schedules and preferred work styles. No matter the timezone, we ensure that our services meet the specific needs and expectations of the project, fostering a collaborative and responsive partnership.
What levels of support do you offer?
We provide comprehensive technical assistance for applications, providing Level 2 and Level 3 support. Within our services, we continuously oversee your applications 24/7, establishing alerts and triggers at vulnerable points to promptly resolve emerging issues. Our team of experts assumes responsibility for alarm management, overseas fundamental technical tasks such as server management, and takes an active role in application development to address security fixes within specified SLAs to ensure support for your operations. In addition, we provide flexible warranty periods on the completion of your project, ensuring ongoing support and satisfaction with our delivered solutions.
Who owns the IP of my application code/will I own the source code?
As our client, you retain full ownership of the source code, ensuring that you have the autonomy and control over your intellectual property throughout and beyond the development process.
How do you manage and accommodate change requests in software development?
We seamlessly handle and accommodate change requests in our software development process through our adoption of the Agile methodology. We use flexible approaches that best align with each unique project and the client's working style. With a commitment to adaptability, our dedicated team is structured to be highly flexible, ensuring that change requests are efficiently managed, integrated, and implemented without compromising the quality of deliverables.
What is the estimated timeline for creating a Minimum Viable Product (MVP)?
The timeline for creating a Minimum Viable Product (MVP) can vary significantly depending on the complexity of the product and the specific requirements of the project. In total, the timeline for creating an MVP can range from around 3 to 9 months, including such stages as Planning, Market Research, Design, Development, Testing, Feedback and Launch.
Do you provide Proof of Concepts (PoCs) during software development?
Yes, we offer Proof of Concepts (PoCs) as part of our software development services. With a proven track record of assisting over 70 companies, our team has successfully built PoCs that have secured initial funding of $10Mn+. Our team helps business owners and units validate their idea, rapidly building a solution you can show in hand. From visual to functional prototypes, we help explore new opportunities with confidence.
Are we able to vet the developers before we take them on-board?
When augmenting your team with our developers, you have the ability to meticulously vet candidates before onboarding. We ask clients to provide us with a required developer’s profile with needed skills and tech knowledge to guarantee our staff possess the expertise needed to contribute effectively to your software development projects. You have the flexibility to conduct interviews, and assess both developers’ soft skills and hard skills, ensuring a seamless alignment with your project requirements.
Is on-demand developer availability among your offerings in software development?
We provide you with on-demand engineers whether you need additional resources for ongoing projects or specific expertise, without the overhead or complication of traditional hiring processes within our staff augmentation service.
Do you collaborate with startups for software development projects?
Yes, our expert team collaborates closely with startups, helping them navigate the technical landscape, build scalable and market-ready software, and bring their vision to life.
Our startup software development services & solutions:
- MVP & Rapid POC's
- Investment & Incubation
- Mobile & Web App Development
- Team Augmentation
- Project Rescue
Subscribe to our blog
Related Posts
Get in Touch with us
Thank You!
Thank you for contacting us, we will get back to you as soon as possible.
Our Next Steps
- Our team reaches out to you within one business day
- We begin with an initial conversation to understand your needs
- Our analysts and developers evaluate the scope and propose a path forward
- We initiate the project, working towards successful software delivery